Как отношения супер-и подтипа в ER-диаграммах представлены в виде таблиц?
Я учусь интерпретировать диаграммы отношений сущностей в операторы SQL DDL, и меня смущают различия в обозначениях. Рассмотрим непересекающиеся отношения, как показано на следующей диаграмме:
будет ли это представлено как:
- таблицы корабля, 2WD и 4WD (2WD и 4WD указали бы к ПК корабля); или
- только таблицы 2WD и 4WD (и никакая таблица корабля), оба из которых дублировали бы все, что угодно атрибуты автомобиля бы?
Я думаю, что это другие способы написания отношений:
Я ищу четкое объяснение разницы в отношении того, какие таблицы вы получите для каждой диаграммы.
4 ответов
ER Notation
есть несколько обозначений ER. Я не знаком с тем, который вы используете, но достаточно ясно, что вы пытаетесь представить подтип (ака. наследование, категория, подкласс, иерархия обобщения...). Это родственник-кузен наследства ООП.
при выполнении подтипов вас обычно беспокоят следующие проектные решения:
-
абстрактные и конкретные: может ли родитель быть инстанцировать? В вашем примере: can a
Vehicleexist без также2WDили4WD?1 -
инклюзивное и эксклюзивное: может ли быть создано более одного ребенка для одного и того же родителя? В вашем примере, может
Vehiclebe и2WDи4WD?2 -
полные и неполные: вы ожидаете, что в будущем будет добавлено больше детей? В вашем примере, вы ожидайте
BikeилиPlane(etc ...) может быть позже добавлен в модель базы данных?
нотация информационной инженерии различает между включительным и исключительным отношением подтипа. Нотация IDEF1X, с другой стороны, не (напрямую) распознает эту разницу, но она различает полный и неполный подтип (чего IE не делает).
следующая диаграмма из Руководство По Методам ERwin (Глава 5, Подтип Отношения) иллюстрирует разницу:
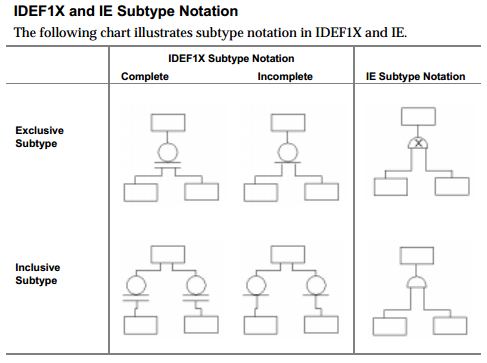
ни IE, ни IDEF1X напрямую не позволяют указывать абстрактный или конкретный родитель.
Физическое Представление
к сожалению, практические базы данных напрямую не поддерживают наследование, поэтому вам нужно преобразование эта диаграмма для реальных таблиц. Для этого обычно существует 3 подхода:
- Поместите все классы в одну таблицу и оставьте дочерние поля NULL-able. Затем вы можете проверить, чтобы убедиться, что правильное подмножество полей в ненулевом.
- плюсы: нет присоединения, поэтому некоторые запросы могут принести пользу. Может применять ключи родительского уровня (например, если вы хотите избежать разных
2WDи4WDтранспортные средства, имеющие тот же идентификатор). Может легко применять инклюзивные и эксклюзивные дети и абстрактные и конкретные родители (просто изменяя проверку). - минусы: некоторые запросы могут быть медленными, так как они должны фильтровать "неинтересные" дети. В зависимости от вашей СУБД, дочерние ограничения могут быть проблематичными. Многие "нулевые" могут тратить время на хранение. Менее подходит для неполного подтипа-добавление нового дочернего элемента требует изменения существующей таблицы, что может быть проблематично в производственной среде.
- плюсы: нет присоединения, поэтому некоторые запросы могут принести пользу. Может применять ключи родительского уровня (например, если вы хотите избежать разных
- поместите всех детей в отдельные таблицы, но не имеют таблицы для родителя (вместо этого повторите родительские поля и ограничения во всех детях). Имеет большинство характеристик (3) избегая соединений, ценой более низкой ремонтопригодности (из-за всех этих полей и повторений ограничений) и невозможности принудительного применения ключей родительского уровня или представления конкретного родителя.
- поместите обоих родителей и детей в отдельные таблицы.
- Плюсы: Чистый. Нет необходимости искусственно повторять поля/ограничения. Применяет ключи родительского уровня и легко добавляет ограничения для детей. Подходит для неполного подтипа (относительно легко добавить больше дочерних таблиц). Некоторые запросы могут выиграть, только посмотрев на" интересные " дочерние таблицы.
- минусы: некоторые запросы могут быть JOIN-heavy. Может быть трудно обеспечить инклюзивные и эксклюзивные дочерние элементы и абстрактные и конкретные родительские элементы (они могут быть применены декларативно, если СУБД поддерживает circular и отложенные внешние ключи, но их применение на уровне приложений обычно считается меньшим злом).
как вы можете видеть, ситуация менее чем идеально - вам нужно будет идти на компромиссы, какой бы подход вы ни выбрали. Подход (3), вероятно, должен быть вашей отправной точкой и выбирать только одну из альтернатив, если есть веская причина для этого.
1 я полагаю, это то, что толщина линии в схемах.
2 я предполагаю, что это то, что означает наличие или отсутствие "непересекающихся" в вашем диаграммы.
Что сказали другие ответчики, плюс следующее, которое входит в первичные ключи для таблиц подклассов.
ваш случай выглядит как экземпляр шаблона проектирования, известного как" специализация обобщения", или Gen-Spec для краткости. Вопрос о том, как моделировать gen-spec с использованием таблиц базы данных, возникает все время в SO.
Если бы вы моделировали gen-spec в OOPL, таком как Java, вы бы использовали средство наследования подкласса, чтобы позаботиться о деталях для вас. Вы просто определите класс для ухода за обобщенными объектами, а затем определите коллекцию подклассов, по одному для каждого типа специализированного объекта. Каждый подкласс расширял бы обобщенный класс. Это легко и просто.
к сожалению, реляционная модель данных не имеет встроенного наследования подклассов, и системы баз данных SQL не предлагают такого средства, насколько мне известно. Но тебе повезло. Вы можете конструировать ваши таблицы для того чтобы моделировать gen-spec в a способ, параллельный структуре классов ООП. Затем необходимо организовать реализацию собственного механизма наследования при добавлении новых элементов в обобщенный класс. Подробности следуют.
структура класса довольно проста, с одной таблицей для класса gen и одной таблицей для каждого подкласса spec. Вот хорошая иллюстрация с сайта Мартина Фаулера. Наследование Таблицы Классов. обратите внимание, что на этой диаграмме игрок в крикет является подклассом и суперклассом. Вы нужно выбрать, какие атрибуты в таблицах. На диаграмме показан один пример атрибута в каждой таблице.
сложная деталь - это то, как вы определяете первичные ключи для этих таблиц. Таблица классов gen получает первичный ключ обычным способом (если эта таблица не является специализацией еще одного обобщения, такого как крикетисты). Большинство дизайнеров дают первичному ключу стандартное имя, например "Id". Они используют функцию autonumber для заполнения поля Id. Таблицы класса spec получают первичный ключ, который можно назвать "Id", но функция autonumber не используется. Вместо этого первичный ключ каждой таблицы подкласса ограничен ссылкой на первичный ключ обобщенной таблицы. Это делает каждый из специализированных первичных ключей внешним ключом, а также первичным ключом. Обратите внимание, что в случае войны, поле ID будет ссылаться на ID поле в игроков, но поле ID в котелки ссылка на поле ID в крикет.
теперь, когда вы добавляете новые элементы, у вас есть чтобы сохранить целостность ссылок, вот как.
Сначала вы вставляете новую строку в таблицу gen, предоставляя данные для всех ее атрибутов, кроме первичного ключа. Механизм autonumber генерирует уникальный первичный ключ. Затем вы вставляете новую строку в соответствующую таблицу спецификаций, включая данные для всех ее атрибутов, включая первичный ключ. Первичный ключ, который вы используете, является копией только что созданного нового первичного ключа. Это распространение первичного ключа можно назвать "бедным человеком". наследование."
теперь, когда вы хотите, чтобы все обобщенные данные вместе со всеми специализированными данные только из одного подкласса, все, что вам нужно сделать, это соединить две таблицы по общей ключей. Все данные, которые не относятся к рассматриваемому подклассу, выпадут из соединения. Это ловко, легко и быстро.
обычно, когда вы делаете связь супер-типа / подтипа в своем дизайне базы данных, вам нужно создать отдельную таблицу для вашего общего типа сущности (супер-типа) и отдельные таблицы для вашей специализированной версии сущности/s (подтипа) несвязанными или нет. В вашем случае вам нужно будет создать таблицу для транспортного средства и первичный ключ и некоторые атрибуты, которые являются общими или общими для всех подтипов. Затем, вам нужно будет создать отдельные таблицы для 2WD и 4WD вместе с атрибутами только для этих таблиц. Например

тогда вы можете запросить эти таблицы с помощью SQL Joins
не всегда существует только один способ реализации какой-либо конкретной модели данных. Часто при переходе от логической модели к физической происходит преобразование.
стандартный SQL не имеет "чистый" способ применения непересекающихся ограничения подтипа.
Если ваша цель состоит в том, чтобы применить как можно больше правил вашей модели, используя схему, то стандартный подход к реализации вашей модели заключается в использовании таблицы для супертайпа и для каждого из подтипов. Это гарантирует, что для каждой сущности используются только применимые атрибуты.
существует более или менее стандартный трюк SQL для обеспечения непересекающегося ограничения. Это отталкивает некоторых людей, потому что это нарушает правила нормализации незначительным образом. Тем не менее, некоторые люди считают технику эстетически оскорбительной, поскольку существует техническое нарушение 2NF.
этот метод включает в себя добавление атрибут разметки к супертип и включение этого атрибута секционирования в каждый подтип, добавление его в первичный ключ подтипа. Наряду с ограничениями check, которые накладывают определенные значения для атрибутов секционирования, это гарантирует, что каждая сущность может иметь не более одного подтипа. Методика описана подробно во многих местах, таких как этот блог.