Как перебирать строку UTF-8 в PHP?
как выполнить итерацию строкового символа UTF-8 с помощью индексирования?
при доступе к строке UTF-8 с помощью оператора скобки $str[0] символ в кодировке utf состоит из 2 или более элементов.
например:
$str = "Kąt";
$str[0] = "K";
$str[1] = "�";
$str[2] = "�";
$str[3] = "t";
но я хотел бы иметь:
$str[0] = "K";
$str[1] = "ą";
$str[2] = "t";
возможно с mb_substr но это очень медленно, т. е.
mb_substr($str, 0, 1) = "K"
mb_substr($str, 1, 1) = "ą"
mb_substr($str, 2, 1) = "t"
есть другой способ interate строку посимвольно без используя mb_substr?
7 ответов
использовать функции preg_split. С модификатор"u" он поддерживает UTF-8 unicode.
$chrArray = preg_split('//u', $str, -1, PREG_SPLIT_NO_EMPTY);
Preg split завершит работу с очень большими строками с исключением памяти и mb_substr действительно медленный, поэтому вот простой и эффективный код, который, я уверен, вы могли бы использовать:
function nextchar($string, &$pointer){
if(!isset($string[$pointer])) return false;
$char = ord($string[$pointer]);
if($char < 128){
return $string[$pointer++];
}else{
if($char < 224){
$bytes = 2;
}elseif($char < 240){
$bytes = 3;
}elseif($char < 248){
$bytes = 4;
}elseif($char == 252){
$bytes = 5;
}else{
$bytes = 6;
}
$str = substr($string, $pointer, $bytes);
$pointer += $bytes;
return $str;
}
}
Это я использовал для зацикливания многобайтовой строки char на char, и если я изменю ее на код ниже, разница в производительности будет огромной:
function nextchar($string, &$pointer){
if(!isset($string[$pointer])) return false;
return mb_substr($string, $pointer++, 1, 'UTF-8');
}
использование его для цикла строки в течение 10000 раз с приведенным ниже кодом привело к 3-секундной среде выполнения для первого код и 13 секунд для второго кода:
function microtime_float(){
list($usec, $sec) = explode(' ', microtime());
return ((float)$usec + (float)$sec);
}
$source = 'árvíztűrő tükörfúrógépárvíztűrő tükörfúrógépárvíztűrő tükörfúrógépárvíztűrő tükörfúrógépárvíztűrő tükörfúrógép';
$t = Array(
0 => microtime_float()
);
for($i = 0; $i < 10000; $i++){
$pointer = 0;
while(($chr = nextchar($source, $pointer)) !== false){
//echo $chr;
}
}
$t[] = microtime_float();
echo $t[1] - $t[0].PHP_EOL.PHP_EOL;
в ответ на комментарии, опубликованные @Pekla и @coL. Shrapnel я сравнил preg_split С mb_substr.
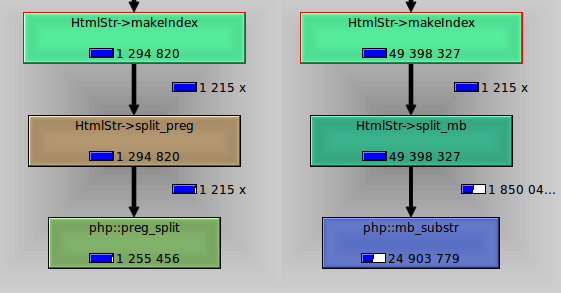
изображение показывает, что preg_split взял 1.2 s, в то время как mb_substr почти 25s.
вот код функции:
function split_preg($str){
return preg_split('//u', $str, -1);
}
function split_mb($str){
$length = mb_strlen($str);
$chars = array();
for ($i=0; $i<$length; $i++){
$chars[] = mb_substr($str, $i, 1);
}
$chars[] = "";
return $chars;
}
используя Лайош Месарош' замечательная функция как вдохновение я создал многобайтовый класс итератора строк.
// Multi-Byte String iterator class
class MbStrIterator implements Iterator
{
private $iPos = 0;
private $iSize = 0;
private $sStr = null;
// Constructor
public function __construct(/*string*/ $str)
{
// Save the string
$this->sStr = $str;
// Calculate the size of the current character
$this->calculateSize();
}
// Calculate size
private function calculateSize() {
// If we're done already
if(!isset($this->sStr[$this->iPos])) {
return;
}
// Get the character at the current position
$iChar = ord($this->sStr[$this->iPos]);
// If it's a single byte, set it to one
if($iChar < 128) {
$this->iSize = 1;
}
// Else, it's multi-byte
else {
// Figure out how long it is
if($iChar < 224) {
$this->iSize = 2;
} else if($iChar < 240){
$this->iSize = 3;
} else if($iChar < 248){
$this->iSize = 4;
} else if($iChar == 252){
$this->iSize = 5;
} else {
$this->iSize = 6;
}
}
}
// Current
public function current() {
// If we're done
if(!isset($this->sStr[$this->iPos])) {
return false;
}
// Else if we have one byte
else if($this->iSize == 1) {
return $this->sStr[$this->iPos];
}
// Else, it's multi-byte
else {
return substr($this->sStr, $this->iPos, $this->iSize);
}
}
// Key
public function key()
{
// Return the current position
return $this->iPos;
}
// Next
public function next()
{
// Increment the position by the current size and then recalculate
$this->iPos += $this->iSize;
$this->calculateSize();
}
// Rewind
public function rewind()
{
// Reset the position and size
$this->iPos = 0;
$this->calculateSize();
}
// Valid
public function valid()
{
// Return if the current position is valid
return isset($this->sStr[$this->iPos]);
}
}
его можно использовать так
foreach(new MbStrIterator("Kąt") as $c) {
echo "{$c}\n";
}
который выведет
K
ą
t
или если вы действительно хотите знать положение начального байта, а также
foreach(new MbStrIterator("Kąt") as $i => $c) {
echo "{$i}: {$c}\n";
}
который выведет
0: K
1: ą
3: t
вы можете проанализировать каждый байт строки и определить, является ли это одним (ASCII) символом или запуск многобайтового символа:
кодировка UTF-8 имеет переменную ширину, каждый символ представлен от 1 до 4 байт. Каждый байт имеет 0-4 ведущих последовательных бита "1", за которыми следует бит "0", чтобы указать его тип. 2 или более " 1 " бит указывает на первый байт в последовательности из этого количества байтов.
вы пройдете через string и вместо увеличения позиции на 1 Прочитайте текущий символ полностью, а затем увеличьте позицию на длину этого символа.
статья Википедии имеет таблицу интерпретации для каждого символа [проверено 2010-10-01]:
0-127 Single-byte encoding (compatible with US-ASCII)
128-191 Second, third, or fourth byte of a multi-byte sequence
192-193 Overlong encoding: start of 2-byte sequence,
but would encode a code point ≤ 127
........
у меня была та же проблема, что и OP, и я пытаюсь избежать регулярного выражения в PHP, так как он терпит неудачу или даже сбой с длинными строками. Я использовал Mészáros Lajos ' ответ С некоторыми изменениями, так как у меня mbstring.func_overload значение 7.
function nextchar($string, &$pointer, &$asciiPointer){
if(!isset($string[$asciiPointer])) return false;
$char = ord($string[$asciiPointer]);
if($char < 128){
$pointer++;
return $string[$asciiPointer++];
}else{
if($char < 224){
$bytes = 2;
}elseif($char < 240){
$bytes = 3;
}elseif($char < 248){
$bytes = 4;
}elseif($char = 252){
$bytes = 5;
}else{
$bytes = 6;
}
$str = substr($string, $pointer++, 1);
$asciiPointer+= $bytes;
return $str;
}
}
С mbstring.func_overload набор в 7, substr на самом деле называет mb_substr. Так что substr возвращает правильное значение в этом случае. Мне пришлось добавить второй указатель. Один отслеживает многобайтовый символ в строке, другой отслеживает однобайтовый символ. Этот многобайтовое значение используется для substr (так как это на самом деле mb_substr), в то время как однобайтовое значение используется для извлечения байта таким образом: $string[$index].
очевидно, что если PHP когда-либо решит исправить доступ [] для правильной работы с многобайтовыми значениями, это не удастся. Но, кроме того, это исправление не понадобится в первую очередь.
Я думаю, что наиболее эффективным решением было бы работать через строку с помощью mb_substr. На каждой итерации цикла mb_substr вызывается дважды (чтобы найти следующий символ и оставшуюся строку). Он передаст только оставшуюся строку на следующую итерацию. Таким образом, основными накладными расходами на каждой итерации будет поиск следующего символа (выполняется дважды), который занимает от одной до пяти операций, в зависимости от длины байта символа.
Если этот описание не ясно, дайте мне знать, и я предоставлю рабочую функцию PHP.