Как реализовать полиморфные ассоциации в существующей базе данных
полиморфные ассимиляции (PA) - это довольно много для относительно простого требования к базе данных: пусть различные таблицы имеют дочерние записи в одной общей таблице. Классический пример-одна таблица с записями комментариев, которые применяются к различным не обязательно родственным сущностям.
на этот вопрос Марк проделал отличную работу, показав три общих подхода к реализации PA. Я хочу использовать подход базовой таблицы, который более подробно описан в одинаково отлично!--5-->ответ Билл Karwin.
конкретный пример будет выглядеть так:
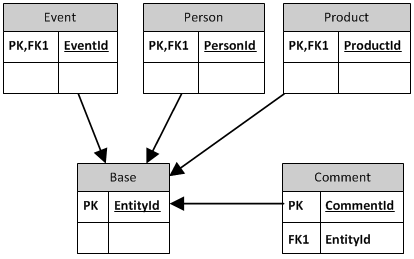
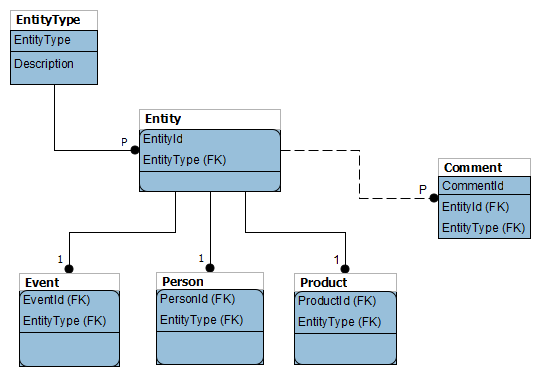
первичные ключи сущностей ссылаются на идентичные значения ключей в базовой таблице, а таблица комментариев ссылается на базовую таблицу, поэтому наблюдается ссылочная целостность. Решающая часть здесь заключается в том, что первичные ключи таблиц сущностей имеют distinct Домены. Они генерируются путем создания новой записи в базе таблица и копирование сгенерированного ключа в первичный ключ сущности.
теперь мой вопрос: что делать, если я хочу представить PA с ссылочной целостностью в существующей базе данных, имеющей сущности, которые генерируют свои собственные, взаимно перекрывающиеся первичные ключи?
пока я вижу два варианта:
Вариант 1:
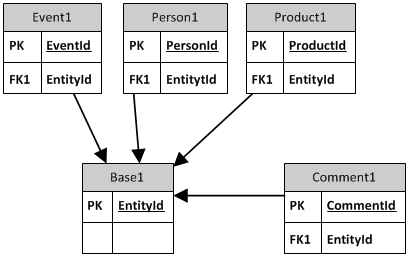
каждый объект сохраняет свой собственный первичный ключ, но также получает альтернативный ключ.
Как:
- близко к рекомендуемому подходу.
- базовая таблица стабильна.
не понравилось:
- существующие объекты должны быть изменены.
- трудно найти объект-владелец комментария.
Вариант 2:
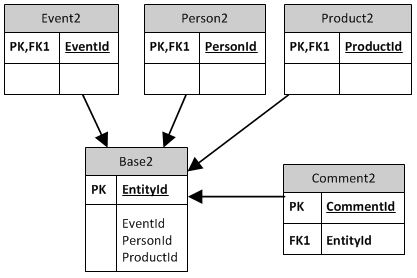
каждый объект имеет свой собственный столбец внешнего ключа в базовой таблице. Это похоже на множественный столбец Марка подход.
Как:
- существующие объекты не затронуты.
- легко найти объект-владелец комментария.
не понравилось:
- разреженные столбцы
- базовая таблица не стабильна: нуждается в модификации, когда вводится новый объект с PA
Я склоняюсь к варианту 1, возможно, с полем "EntityName" в базовой таблице для двунаправленного поиска. какой вариант будет лучше. Или другой, еще лучший подход?
1 ответов
вы можете использовать Вариант 1, но без дополнительного суррогатного альтернативного ключа.
вместо этого расширьте существующий первичный ключ (каждого объекта) с помощью (скажем CHAR(1), что бы E событий, P для лиц, D для продуктов).
соединение (EntityId, EntityType) станет тогда первичным ключом таблицы Entity и соответствующие соединения в других 3 таблицах подтипов.
(The EntityType Это просто вспомогательный, ссылка стол, с 3 строк):