Как создать новые полигоны путем упрощения из двух объектов SpatialPolygonsDataFrame в R?
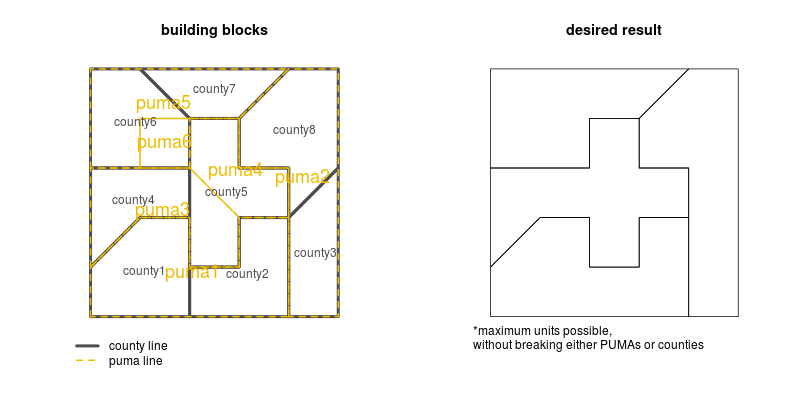
скажем, у меня есть два набора файлов формы, которые охватывают один и тот же регион и часто, но не всегда разделяют границы, например, округа США и пумы. Я хотел бы определить новый масштаб многоугольника, который использует как пумы, так и графства в качестве атомарных строительных блоков, т. е. ни один из них никогда не может быть разделен, но мне все равно нужно как можно больше единиц. Вот пример игрушки:
library(sp)
# make fake data
# 1) counties:
Cty <- SpatialPolygons(list(
Polygons(list(Polygon(cbind(x=c(0,2,2,1,0,0),y=c(0,0,2,2,1,0)), hole=FALSE)),"county1"),
Polygons(list(Polygon(cbind(x=c(2,4,4,3,3,2,2),y=c(0,0,2,2,1,1,0)),hole=FALSE)),"county2"),
Polygons(list(Polygon(cbind(x=c(4,5,5,4,4),y=c(0,0,3,2,0)),hole=FALSE)),"county3"),
Polygons(list(Polygon(cbind(x=c(0,1,2,2,0,0),y=c(1,2,2,3,3,1)),hole=FALSE)),"county4"),
Polygons(list(Polygon(cbind(x=c(2,3,3,4,4,3,3,2,2),y=c(1,1,2,2,3,3,4,4,1)),hole=FALSE)),"county5"),
Polygons(list(Polygon(cbind(x=c(0,2,2,1,0,0),y=c(3,3,4,5,5,3)),hole=FALSE)),"county6"),
Polygons(list(Polygon(cbind(x=c(1,2,3,4,1),y=c(5,4,4,5,5)),hole=FALSE)),"county7"),
Polygons(list(Polygon(cbind(x=c(3,4,4,5,5,4,3,3),y=c(3,3,2,3,5,5,4,3)),hole=FALSE)),"county8")
))
counties <- SpatialPolygonsDataFrame(Cty, data = data.frame(ID=paste0("county",1:8),
row.names=paste0("county",1:8),
stringsAsFactors=FALSE)
)
# 2) PUMAs:
Pum <- SpatialPolygons(list(
Polygons(list(Polygon(cbind(x=c(0,4,4,3,3,2,2,1,0,0),y=c(0,0,2,2,1,1,2,2,1,0)), hole=FALSE)),"puma1"),
Polygons(list(Polygon(cbind(x=c(4,5,5,4,3,3,4,4),y=c(0,0,5,5,4,3,3,0)),hole=FALSE)),"puma2"),
Polygons(list(Polygon(cbind(x=c(0,1,2,2,3,3,2,0,0),y=c(1,2,2,1,1,2,3,3,1)),hole=FALSE)),"puma3"),
Polygons(list(Polygon(cbind(x=c(2,3,4,4,3,3,2,2),y=c(3,2,2,3,3,4,4,3)),hole=FALSE)),"puma4"),
Polygons(list(Polygon(cbind(x=c(0,1,1,3,4,0,0),y=c(3,3,4,4,5,5,3)),hole=FALSE)),"puma5"),
Polygons(list(Polygon(cbind(x=c(1,2,2,1,1),y=c(3,3,4,4,3)),hole=FALSE)),"puma6")
))
Pumas <- SpatialPolygonsDataFrame(Pum, data = data.frame(ID=paste0("puma",1:6),
row.names=paste0("puma",1:6),
stringsAsFactors=FALSE)
)
# desired result:
Cclust <- SpatialPolygons(list(
Polygons(list(Polygon(cbind(x=c(0,4,4,3,3,2,2,1,0,0),y=c(0,0,2,2,1,1,2,2,1,0)), hole=FALSE)),"ctyclust1"),
Polygons(list(Polygon(cbind(x=c(4,5,5,4,3,3,4,4),y=c(0,0,5,5,4,3,3,0)),hole=FALSE)),"ctyclust2"),
Polygons(list(Polygon(cbind(x=c(0,1,2,2,3,3,4,4,3,3,2,2,0,0),y=c(1,2,2,1,1,2,2,3,3,4,4,3,3,1)),hole=FALSE)),"ctyclust3"),
Polygons(list(Polygon(cbind(x=c(0,2,2,3,4,0,0),y=c(3,3,4,4,5,5,3)),hole=FALSE)),"ctyclust4")
))
CtyClusters <- SpatialPolygonsDataFrame(Cclust, data = data.frame(ID = paste0("ctyclust", 1:4),
row.names = paste0("ctyclust", 1:4),
stringsAsFactors=FALSE)
)
# take a look
par(mfrow = c(1, 2))
plot(counties, border = gray(.3), lwd = 4)
plot(Pumas, add = TRUE, border = "#EEBB00", lty = 2, lwd = 2)
legend(-.5, -.3, lty = c(1, 2), lwd = c(4, 2), col = c(gray(.3), "#EEBB00"),
legend = c("county line", "puma line"), xpd = TRUE, bty = "n")
text(coordinates(counties), counties@data$ID,col = gray(.3))
text(coordinates(Pumas), Pumas@data$ID, col = "#EEBB00",cex=1.5)
title("building blocks")
#desired result:
plot(CtyClusters)
title("desired result")
text(-.5, -.5, "maximum units possible,nwithout breaking either PUMAs or counties",
xpd = TRUE, pos = 4)
 Я наивно пробовал многие функции g* в пакете rgeos для достижения этого и не продвинулся вперед. Делает кто-нибудь знает о хорошей функции или удивительном трюке для этой задачи? Спасибо!
Я наивно пробовал многие функции g* в пакете rgeos для достижения этого и не продвинулся вперед. Делает кто-нибудь знает о хорошей функции или удивительном трюке для этой задачи? Спасибо!
[Я также открыт для предложений по лучшему названию]
3 ответов
вот относительно краткое решение, которое:
использует
rgeos::gRelate()чтобы определить пумы, которые перекрываются, но не полностью охватывают / охватывают каждый округ.Чтобы понять, что он делает, запуститеexample(gRelate)и видим эта страница Википедии. (ч. Т. Тим Риффа)использует
RBGL::connectedComp()для определения групп пумы, которые должны быть объединены. (Для указателей на установку RBGL см. Мой ответ это так вопрос.)-
использует
rgeos::gUnionCascaded()объединить указанные пумы.library(rgeos) library(RBGL) ## Identify groups of Pumas that should be merged x <- gRelate(counties, Pumas, byid=TRUE) x <- matrix(grepl("2.2......", x), ncol=ncol(x), dimnames=dimnames(x)) k <- x %*% t(x) l <- connectedComp(as(k, "graphNEL")) ## Extend gUnionCascaded so that each SpatialPolygon gets its own ID. gMerge <- function(ii) { x <- gUnionCascaded(Pumas[ii,]) spChFIDs(x, paste(ii, collapse="_")) } ## Merge Pumas as needed res <- do.call(rbind, sapply(l, gMerge)) plot(res)
Я думаю, вы могли бы сделать это с помощью умного набора тестов для сдерживания. Это получает две ваши части, простой парный случай, где puma1 содержит county1 и county2 и puma2 содержит county8 и county3.
library(rgeos)
## pumas by counties
pbyc <- gContains(Pumas, counties, byid = TRUE)
## row / col pairs of where contains test is TRUE for Pumas
pbyc.pairs <- cbind(row(pbyc)[pbyc], col(pbyc)[pbyc])
par(mfrow = c(nrow(pbyc.pairs), 1))
for (i in 1:nrow(pbyc.pairs)) {
plot(counties, col = "white")
plot(gUnion(counties[pbyc.pairs[i,1], ], Pumas[pbyc.pairs[i,2], ]), col = "red", add = TRUE)
}
заговор там тупо избыточен, но я думаю, что это показывает начало. Вам нужно найти, какие содержит тесты накапливать наиболее мелкие части, а затем объединить их. Извините, я не приложил усилий, чтобы закончить, но я думаю, что это сработает.
после многих проб и ошибок я придумал следующее неэлегантное решение, скорее в соответствии с подсказкой @mdsummer, но добавляя больше проверок, удаляя избыточные объединенные полигоны и проверяя. Хлоп. Если кто-то может взять то, что я сделал, и сделать его чище, тогда я приму этот ответ, а это, чего я хотел бы избежать, если это вообще возможно:
library(rgeos)
pbyc <- gCovers(Pumas, counties, byid = TRUE) |
gContains(Pumas, counties, byid = TRUE) |
gOverlaps(Pumas, counties, byid = TRUE) |
t(gCovers(counties, Pumas, byid = TRUE) |
gContains(counties, Pumas, byid = TRUE) |
gOverlaps(counties, Pumas, byid = TRUE))
## row / col pairs of where test is TRUE for Pumas or counties
pbyc.pairs <- cbind(row(pbyc)[pbyc], col(pbyc)[pbyc])
Potentials <- apply(pbyc.pairs, 1, function(x,counties,Pumas){
gUnion(counties[x[1], ], Pumas[x[2], ])
}, counties = counties, Pumas= Pumas)
for (i in 1:length(Potentials)){
Potentials[[i]]@polygons[[1]]@ID <- paste0("p",i)
}
Potentials <- do.call("rbind",Potentials)
# remove redundant polygons:
Redundants <- gEquals(Potentials, byid = TRUE)
Redundants <- row(Redundants)[Redundants & lower.tri(Redundants)]
Potentials <- Potentials[-c(Redundants),]
# for each Potential summary polygon, see which counties and Pumas are contained:
keep.i <- vector(length=length(Potentials))
for (i in 1:length(Potentials)){
ctyblocki <- gUnionCascaded(counties[c(gCovers(Potentials[i, ], counties, byid = TRUE)), ])
Pumablocki <- gUnionCascaded(Pumas[c(gCovers(Potentials[i, ], Pumas, byid = TRUE)), ])
keep.i[i] <- gEquals(ctyblocki, Potentials[i, ]) & gEquals(Pumablocki, Potentials[i, ])
}
# what do we have left?
NewUnits <- Potentials[keep.i, ]
plot(NewUnits)