Как ускорить выполнение tensorflow на hadoop?
следующий скрипт выполняется очень медленно. Я просто хочу подсчитать общее количество строк в twitter-follwer-graph (textfile с ~26 GB).
мне нужно выполнить задачу машинного обучения. Это просто тест на доступ к данным из hdfs с помощью tensorflow.
import tensorflow as tf
import time
filename_queue = tf.train.string_input_producer(["hdfs://default/twitter/twitter_rv.net"], num_epochs=1, shuffle=False)
def read_filename_queue(filename_queue):
reader = tf.TextLineReader()
_, line = reader.read(filename_queue)
return line
line = read_filename_queue(filename_queue)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1500,inter_op_parallelism_threads=1500)
with tf.Session(config=session_conf) as sess:
sess.run(tf.initialize_local_variables())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
start = time.time()
i = 0
while True:
i = i + 1
if i%100000 == 0:
print(i)
print(time.time() - start)
try:
sess.run([line])
except tf.errors.OutOfRangeError:
print('end of file')
break
print('total number of lines = ' + str(i))
print(time.time() - start)
процесс требует около 40 секунд для первых 100000 строк.
Я пытался установить intra_op_parallelism_threads и inter_op_parallelism_threads на 0, 4, 8, 40, 400 и 1500. Но это не повлияло на время казни значительно...
вы можете мне помочь?
характеристики системы:
- 16 ГБ ОЗУ
- 4 ядер ЦП
5 ответов
вы можете разделить большой файл на более мелкие, это может помочь. И установите intra_op_parallelism_threads и inter_op_parallelism_threads в 0;
для многих систем чтение одного необработанного текстового файла с несколькими процессами непросто, tensorflow читает один файл только с одним потоком, поэтому настройка потоков tensorflow не поможет. Spark может обрабатывать файл с несколькими потоками для него разделить файл на блоки и каждый поток, считывающий содержимое в строках его блока и игнорирующий символы перед первым \n ибо они принадлежат к последней строке последнего блока. Для пакетной обработки данных Spark-лучший выбор, в то время как tensorflow лучше подходит для задач машинного обучения/глубокого обучения;
Я также новичок, работающий с tensorflow, но так как вы спрашивали для ответов, полученных из надежных и / или официальных источников, вот что я нашел и мог бы помочь:
- сборка и установка из исходников
- использовать очереди для чтения данных
- предварительная обработка на CPU
- используйте формат данных изображения NCHW
- разместить общие параметры на GPU
- использовать плавленый партии норма!--6-->
Примечание: пункты перечисленные выше объяснены более подробно здесь в руководство по производительности tensorflow
еще одна вещь, которую вы можете захотеть изучить, это квантования:
что может объяснить, как использовать квантование для уменьшения размера модели, как в хранилище, так и во время выполнения. Квантование может повысить производительность, особенно на мобильных устройств.
https://github.com/linkedin/TonY
С Тони вы можете отправить задание TensorFlow и указать количество рабочих и требуется ли им процессоры или графические процессоры.
мы смогли получить почти линейное ускорение при работе на нескольких серверах с TonY (модель Inception v3):
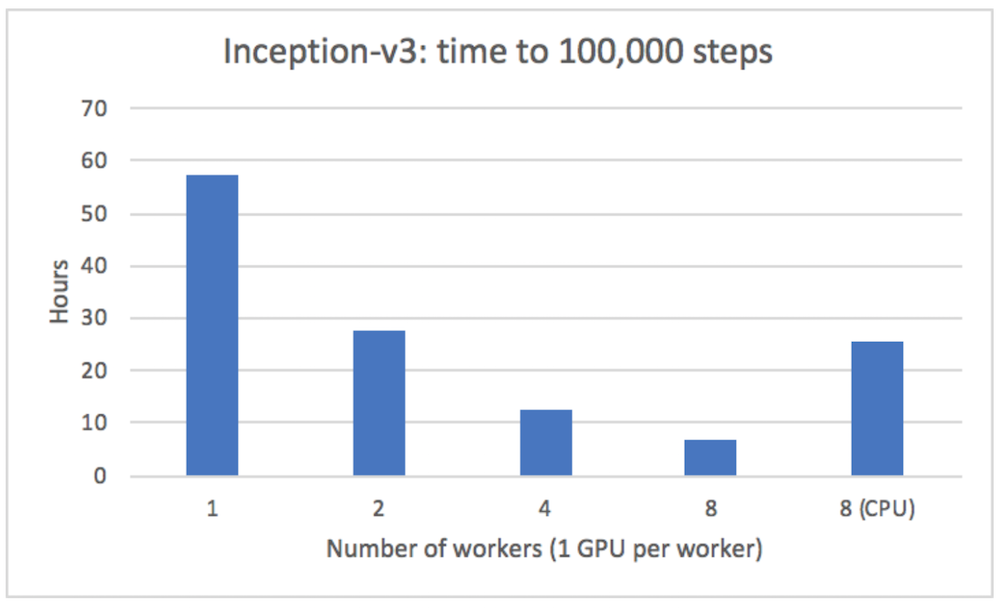
Ниже приведен пример того, как использовать его из README:
на tony каталог также есть tony.xml, который содержит все Тони джоб.
Например:
$ cat tony/tony.xml
<configuration>
<property>
<name>tony.worker.instances</name>
<value>4</value>
</property>
<property>
<name>tony.worker.memory</name>
<value>4g</value>
</property>
<property>
<name>tony.worker.gpus</name>
<value>1</value>
</property>
<property>
<name>tony.ps.memory</name>
<value>3g</value>
</property>
</configuration>
полный список конфигураций см. в wiki.
Типовой кодекс$ ls src/models/ | grep mnist_distributed
mnist_distributed.py
тогда вы можете запустить свою работу:
$ java -cp "`hadoop classpath --glob`:tony/*:tony" \
com.linkedin.tony.cli.ClusterSubmitter \
-executes src/models/mnist_distributed.py \
-task_params '--input_dir /path/to/hdfs/input --output_dir /path/to/hdfs/output --steps 2500 --batch_size 64' \
-python_venv my-venv.zip \
-python_binary_path Python/bin/python \
-src_dir src \
-shell_env LD_LIBRARY_PATH=/usr/java/latest/jre/lib/amd64/server
аргументы командной строки следующие:
* executes описывает расположение к точке входа вашего обучения код.
* task_params опишите аргументы командной строки, которые будут переданы в вашу точку входа.
* python_venv описывает имя zip локально, который будет вызывать ваш скрипт Python.
* python_binary_path описывает относительный путь в виртуальной среде python, который содержит двоичный файл python, или абсолютный путь для использования двоичного файла python, уже установленного на всех рабочих узлах.
* src_dir задает имя корневого каталога локально, который содержит весь исходный код модели python. Этот каталог будет скопирован на все рабочие узлы.
* shell_env задает пары ключ-значение для переменных среды, которые будут установлены в вашем python worker / ps процессы.
попробовать это, и это должно улучшить ваше время:
session_conf = tf.ConfigProto
(intra_op_parallelism_threads=0,inter_op_parallelism_threads=0)
нехорошо брать конфиг в свои руки, когда вы не знаете, что такое оптимальное значение.