Как заменить каждый 0 предыдущим элементом в списке идиоматическим способом в Mathematica?
это забавная маленькая проблема, и я хотел проверить у экспертов здесь, есть ли лучший функциональный/математический способ подойти к ее решению, чем то, что я сделал. Я не слишком доволен своим решением, так как я использую big IF, но не могу найти команду Mathematica, чтобы легко использовать ее (например,Select, Cases, Sow/Reap, Map.. так далее...)
вот проблема, учитывая значения списка( числа или символы), но для простоты предположим, что список пока цифры. Список может содержать нули, и цель состоит в том, чтобы заменить каждый нуль элементом, видимым перед ним.
в конце в списке не должно быть нулей.
вот пример, приведенный
a = {1, 0, 0, -1, 0, 0, 5, 0};
результат должен быть
a = {1, 1, 1, -1, -1, -1, 5, 5}
это, конечно, должно быть сделано наиболее эффективным способом.
это то, что я мог придумать
Scan[(a[[#]] = If[a[[#]] == 0, a[[#-1]], a[[#]]]) &, Range[2, Length[a]]];
Я хотел посмотреть, могу ли я использовать Сеять / жать на этом, но не умел.
вопрос: Можно ли это решить более функциональным/Mathematica способом? Чем короче, тем лучше, конечно :)
обновление 1 Спасибо всем за ответ, все очень хорошо учиться. Это результат теста скорости, на V 8.04, используя windows 7, 4 GB Ram, intel 930 @2.8 Ghz:
Я проверил методы, приведенные для n С 100,000 to 4 million. The ReplaceRepeated метод не очень хорошо для больших списков.
обновление 2
удален более ранний результат, который был показан выше в update1 из-за моей ошибки при копировании одного из тестов.
обновленные результаты приведены ниже. Метод Леонида самый быстрый. Поздравляю Леонида. Очень быстрый метод.
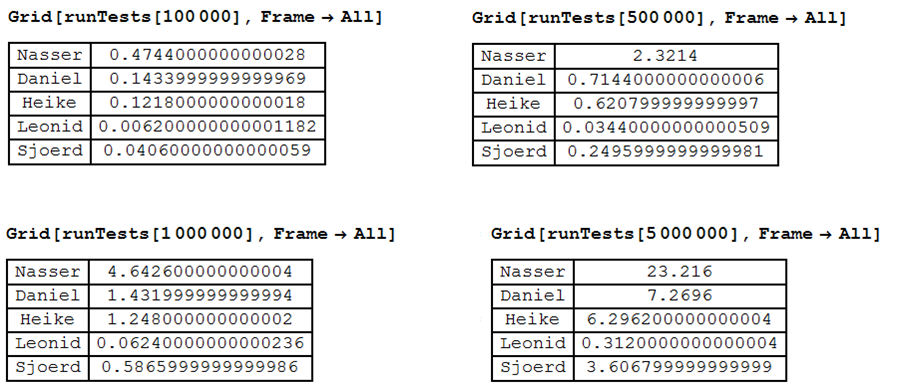
программа тестирования следующая:
(*version 2.0 *)
runTests[sizeOfList_?(IntegerQ[#] && Positive[#] &)] :=
Module[{tests, lst, result, nasser, daniel, heike, leonid, andrei,
sjoerd, i, names},
nasser[lst_List] := Module[{a = lst},
Scan[(a[[#]] = If[a[[#]] == 0, a[[# - 1]], a[[#]]]) &,
Range[2, Length[a]]]
];
daniel[lst_List] := Module[{replaceWithPrior},
replaceWithPrior[ll_, n_: 0] :=
Module[{prev}, Map[If[# == 0, prev, prev = #] &, ll]
];
replaceWithPrior[lst]
];
heike[lst_List] := Flatten[Accumulate /@ Split[lst, (#2 == 0) &]];
andrei[lst_List] := Module[{x, y, z},
ReplaceRepeated[lst, {x___, y_, 0, z___} :> {x, y, y, z},
MaxIterations -> Infinity]
];
leonid[lst_List] :=
FoldList[If[#2 == 0, #1, #2] &, First@#, Rest@#] & @lst;
sjoerd[lst_List] :=
FixedPoint[(1 - Unitize[#]) RotateRight[#] + # &, lst];
lst = RandomChoice[Join[ConstantArray[0, 10], Range[-1, 5]],
sizeOfList];
tests = {nasser, daniel, heike, leonid, sjoerd};
names = {"Nasser","Daniel", "Heike", "Leonid", "Sjoerd"};
result = Table[0, {Length[tests]}, {2}];
Do[
result[[i, 1]] = names[[i]];
Block[{j, r = Table[0, {5}]},
Do[
r[[j]] = First@Timing[tests[[i]][lst]], {j, 1, 5}
];
result[[i, 2]] = Mean[r]
],
{i, 1, Length[tests]}
];
result
]
для запуска тестов длиной 1000 команда есть:
Grid[runTests[1000], Frame -> All]
спасибо всем за ответы.
4 ответов
намного (на порядок) быстрее, чем другие решения:
FoldList[If[#2 == 0, #1, #2] &, First@#, Rest@#] &
ускорение происходит из-за Fold autocompiling. Не будет так драматично для неупакованных массивов. Ориентиры:
In[594]:=
a=b=c=RandomChoice[Join[ConstantArray[0,10],Range[-1,5]],150000];
(b=Flatten[Accumulate/@Split[b,(#2==0)&]]);//Timing
Scan[(a[[#]]=If[a[[#]]==0,a[[#-1]],a[[#]]])&,Range[2,Length[a]]]//Timing
(c=FoldList[If[#2==0,#1,#2]&,First@#,Rest@#]&@c);//Timing
SameQ[a,b,c]
Out[595]= {0.187,Null}
Out[596]= {0.625,Null}
Out[597]= {0.016,Null}
Out[598]= True
это, кажется, Фактор 4 быстрее на моей машине:
a = Flatten[Accumulate /@ Split[a, (#2 == 0) &]]
тайминги я получаю
a = b = RandomChoice[Join[ConstantArray[0, 10], Range[-1, 5]], 10000];
(b = Flatten[Accumulate /@ Split[b, (#2 == 0) &]]); // Timing
Scan[(a[[#]] = If[a[[#]] == 0, a[[# - 1]], a[[#]]]) &,
Range[2, Length[a]]] // Timing
SameQ[a, b]
(* {0.015815, Null} *)
(* {0.061929, Null} *)
(* True *)
FixedPoint[(1 - Unitize[#]) RotateRight[#] + # &, d]
примерно в 10 и 2 раза быстрее, чем решения Хейке, но медленнее, чем решения Леонида.
вы вопрос выглядит точно как задача для ReplaceRepeated. Что он делает в основном, так это то, что он применяет тот же набор правил к выражению до тех пор, пока больше правил не будут применимы. В вашем случае выражение является списком, и правило заключается в замене 0 на его предшественник всякий раз, когда происходит в списке. Итак, вот решение:
a = {1, 0, 0, -1, 0, 0, 5, 0};
a //. {x___, y_, 0, z___} -> {x, y, y, z};
шаблон для правила здесь следующий:
-
x___- любой символ ноль или более повторения, начало списка -
y_- ровно один элемент до нуля -
0- ноль сам по себе, этот элемент будет заменен наyпозже -
z___- любой символ ноль или более повторений, в конце списка