Наиболее эффективный способ вычитать один массив из другого
У меня есть следующий код, который является узким местом в одной части моего приложения. Все, что я делаю, это вычитаю на массиве из другого. Оба этих массива имеют более 100000 элементов. Я пытаюсь найти способ сделать это более эффективным.
var
Array1, Array2 : array of integer;
.....
// Code that fills the arrays
.....
for ix := 0 to length(array1)-1
Array1[ix] := Array1[ix] - Array2[ix];
end;
у кого-нибудь есть предложения?
5 ответов
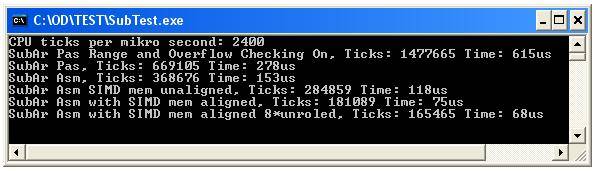
мне было очень интересно оптимизировать скорость в этом простом случае. Поэтому я сделал 6 простых процедур и измерил ТИК процессора и время при размере массива 100000;
- процедура Pascal с диапазоном параметров компилятора и проверкой переполнения на
- процедура Pascal с диапазоном параметров компилятора и проверкой переполнения
- классическая процедура ассемблера x86.
- процедура ассемблера с инструкциями SSE и unaligned 16 байт двигайся!--12-->.
- процедура ассемблера с инструкциями SSE и выровненный 16-байтовый ход.
- ассемблер 8 раз развернул цикл с инструкциями SSE и выровненный 16-байтовый ход.
проверьте результаты на картинке и коде для получения дополнительной информации.
чтобы получить выравнивание памяти 16 байт, сначала удалите точку в файле " FastMM4Options.директива Инк' {$.определять Align16Bytes} !
program SubTest;
{$APPTYPE CONSOLE}
uses
//In file 'FastMM4Options.inc' delite the dot in directive {$.define Align16Bytes}
//to get 16 byte memory alignment!
FastMM4,
windows,
SysUtils;
var
Ar1 :array of integer;
Ar2 :array of integer;
ArLength :integer;
StartTicks :int64;
EndTicks :int64;
TicksPerMicroSecond :int64;
function GetCpuTicks: int64;
asm
rdtsc
end;
{$R+}
{$Q+}
procedure SubArPasRangeOvfChkOn(length: integer);
var
n: integer;
begin
for n := 0 to length -1 do
Ar1[n] := Ar1[n] - Ar2[n];
end;
{$R-}
{$Q-}
procedure SubArPas(length: integer);
var
n: integer;
begin
for n := 0 to length -1 do
Ar1[n] := Ar1[n] - Ar2[n];
end;
procedure SubArAsm(var ar1, ar2; length: integer);
asm
//Length must be > than 0!
push ebx
lea ar1, ar1 - 4
lea ar2, ar2 - 4
@Loop:
mov ebx, [ar2 + length * 4]
sub [ar1 + length * 4], ebx
dec length
jnz @Loop
@exit:
pop ebx
end;
procedure SubArAsmSimdU(var ar1, ar2; length: integer);
asm
//Prepare length
push length
shr length, 2
jz @Finish
@Loop:
movdqu xmm1, [ar1]
movdqu xmm2, [ar2]
psubd xmm1, xmm2
movdqu [ar1], xmm1
add ar1, 16
add ar2, 16
dec length
jnz @Loop
@Finish:
pop length
push ebx
and length, 3
jz @Exit
//Do rest, up to 3 subtractions...
mov ebx, [ar2]
sub [ar1], ebx
dec length
jz @Exit
mov ebx, [ar2 + 4]
sub [ar1 + 4], ebx
dec length
jz @Exit
mov ebx, [ar2 + 8]
sub [ar1 + 8], ebx
@Exit:
pop ebx
end;
procedure SubArAsmSimdA(var ar1, ar2; length: integer);
asm
push ebx
//Unfortunately delphi use first 8 bytes for dinamic array length and reference
//counter, from that reason the dinamic array address should start with $xxxxxxx8
//instead &xxxxxxx0. So we must first align ar1, ar2 pointers!
mov ebx, [ar2]
sub [ar1], ebx
dec length
jz @exit
mov ebx, [ar2 + 4]
sub [ar1 + 4], ebx
dec length
jz @exit
add ar1, 8
add ar2, 8
//Prepare length for 16 byte data transfer
push length
shr length, 2
jz @Finish
@Loop:
movdqa xmm1, [ar1]
movdqa xmm2, [ar2]
psubd xmm1, xmm2
movdqa [ar1], xmm1
add ar1, 16
add ar2, 16
dec length
jnz @Loop
@Finish:
pop length
and length, 3
jz @Exit
//Do rest, up to 3 subtractions...
mov ebx, [ar2]
sub [ar1], ebx
dec length
jz @Exit
mov ebx, [ar2 + 4]
sub [ar1 + 4], ebx
dec length
jz @Exit
mov ebx, [ar2 + 8]
sub [ar1 + 8], ebx
@Exit:
pop ebx
end;
procedure SubArAsmSimdAUnrolled8(var ar1, ar2; length: integer);
asm
push ebx
//Unfortunately delphi use first 8 bytes for dinamic array length and reference
//counter, from that reason the dinamic array address should start with $xxxxxxx8
//instead &xxxxxxx0. So we must first align ar1, ar2 pointers!
mov ebx, [ar2]
sub [ar1], ebx
dec length
jz @exit
mov ebx, [ar2 + 4]
sub [ar1 + 4], ebx
dec length
jz @exit
add ar1, 8 //Align pointer to 16 byte
add ar2, 8 //Align pointer to 16 byte
//Prepare length for 16 byte data transfer
push length
shr length, 5 //8 * 4 subtructions per loop
jz @Finish //To small for LoopUnrolled
@LoopUnrolled:
//Unrolle 1, 2, 3, 4
movdqa xmm4, [ar2]
movdqa xmm5, [16 + ar2]
movdqa xmm6, [32 + ar2]
movdqa xmm7, [48 + ar2]
//
movdqa xmm0, [ar1]
movdqa xmm1, [16 + ar1]
movdqa xmm2, [32 + ar1]
movdqa xmm3, [48 + ar1]
//
psubd xmm0, xmm4
psubd xmm1, xmm5
psubd xmm2, xmm6
psubd xmm3, xmm7
//
movdqa [48 + ar1], xmm3
movdqa [32 + ar1], xmm2
movdqa [16 + ar1], xmm1
movdqa [ar1], xmm0
//Unrolle 5, 6, 7, 8
movdqa xmm4, [64 + ar2]
movdqa xmm5, [80 + ar2]
movdqa xmm6, [96 + ar2]
movdqa xmm7, [112 + ar2]
//
movdqa xmm0, [64 + ar1]
movdqa xmm1, [80 + ar1]
movdqa xmm2, [96 + ar1]
movdqa xmm3, [112 + ar1]
//
psubd xmm0, xmm4
psubd xmm1, xmm5
psubd xmm2, xmm6
psubd xmm3, xmm7
//
movdqa [112 + ar1], xmm3
movdqa [96 + ar1], xmm2
movdqa [80 + ar1], xmm1
movdqa [64 + ar1], xmm0
//
add ar1, 128
add ar2, 128
dec length
jnz @LoopUnrolled
@FinishUnrolled:
pop length
and length, F
//Do rest, up to 31 subtractions...
@Finish:
mov ebx, [ar2]
sub [ar1], ebx
add ar1, 4
add ar2, 4
dec length
jnz @Finish
@Exit:
pop ebx
end;
procedure WriteOut(EndTicks: Int64; Str: string);
begin
WriteLn(Str + IntToStr(EndTicks - StartTicks)
+ ' Time: ' + IntToStr((EndTicks - StartTicks) div TicksPerMicroSecond) + 'us');
Sleep(5);
SwitchToThread;
StartTicks := GetCpuTicks;
end;
begin
ArLength := 100000;
//Set TicksPerMicroSecond
QueryPerformanceFrequency(TicksPerMicroSecond);
TicksPerMicroSecond := TicksPerMicroSecond div 1000000;
//
SetLength(Ar1, ArLength);
SetLength(Ar2, ArLength);
//Fill arrays
//...
//Tick time info
WriteLn('CPU ticks per mikro second: ' + IntToStr(TicksPerMicroSecond));
Sleep(5);
SwitchToThread;
StartTicks := GetCpuTicks;
//Test 1
SubArPasRangeOvfChkOn(ArLength);
WriteOut(GetCpuTicks, 'SubAr Pas Range and Overflow Checking On, Ticks: ');
//Test 2
SubArPas(ArLength);
WriteOut(GetCpuTicks, 'SubAr Pas, Ticks: ');
//Test 3
SubArAsm(Ar1[0], Ar2[0], ArLength);
WriteOut(GetCpuTicks, 'SubAr Asm, Ticks: ');
//Test 4
SubArAsmSimdU(Ar1[0], Ar2[0], ArLength);
WriteOut(GetCpuTicks, 'SubAr Asm SIMD mem unaligned, Ticks: ');
//Test 5
SubArAsmSimdA(Ar1[0], Ar2[0], ArLength);
WriteOut(GetCpuTicks, 'SubAr Asm with SIMD mem aligned, Ticks: ');
//Test 6
SubArAsmSimdAUnrolled8(Ar1[0], Ar2[0], ArLength);
WriteOut(GetCpuTicks, 'SubAr Asm with SIMD mem aligned 8*unrolled, Ticks: ');
//
ReadLn;
Ar1 := nil;
Ar2 := nil;
end.
...
самая быстрая процедура asm с 8 раз развернутыми инструкциями SIMD занимает всего 68us и примерно в 4 раза быстрее, чем процедура Pascal.
Как мы видим, процедура цикла Pascal, вероятно, не критична, она занимает всего около 277us (переполнение и проверка диапазона) на 2,4 ГГц CPU при 100000 вычитаниях.
Так этот код не может быть узким местом?
запуск этого на нескольких потоках, с этим большим массивом будет чистым линейным ускорением. Как говорится, до неловкости параллельна.
запуск вычитания на нескольких потоках звучит хорошо, но 100k integer sunstraction не занимает много времени процессора, поэтому, возможно, threadpool... Однако потоки настроек также имеют много накладных расходов, поэтому короткие массивы будут иметь более низкую производительность в параллельных потоках, чем только в одном (основном) потоке!
вы отключились в настройках компилятора, переполнении и проверке диапазона?
вы можете попробовать использовать ASM rutine, это очень просто...
что-то например:
procedure SubArray(var ar1, ar2; length: integer);
asm
//length must be > than 0!
push ebx
lea ar1, ar1 -4
lea ar2, ar2 -4
@Loop:
mov ebx, [ar2 + length *4]
sub [ar1 + length *4], ebx
dec length
//Here you can put more folloving parts of rutine to more unrole it to speed up.
jz @exit
mov ebx, [ar2 + length *4]
sub [ar1 + length *4], ebx
dec length
//
jnz @Loop
@exit:
pop ebx
end;
begin
SubArray(Array1[0], Array2[0], length(Array1));
это может быть намного быстрее...
EDIT: добавлена процедура с инструкциями SIMD.
Эта процедура запрашивает поддержку процессора SSE. Он может принимать 4 целых числа в регистре XMM и вычитать сразу. Существует также возможность использовать movdqa вместо movdqu это быстрее, но вы должны сначала обеспечить 16 байт aligment. Вы также можете unrole расширения XMM пар, как в моем первом случае АСМ. (Меня интересует измерение скорости. :))
var
array1, array2: array of integer;
procedure SubQIntArray(var ar1, ar2; length: integer);
asm
//prepare length if not rounded to 4
push ecx
shr length, 2
jz @LengthToSmall
@Loop:
movdqu xmm1, [ar1] //or movdqa but ensure 16b aligment first
movdqu xmm2, [ar2] //or movdqa but ensure 16b aligment first
psubd xmm1, xmm2
movdqu [ar1], xmm1 //or movdqa but ensure 16b aligment first
add ar1, 16
add ar2, 16
dec length
jnz @Loop
@LengthToSmall:
pop ecx
push ebx
and ecx, 3
jz @Exit
mov ebx, [ar2]
sub [ar1], ebx
dec ecx
jz @Exit
mov ebx, [ar2 + 4]
sub [ar1 + 4], ebx
dec ecx
jz @Exit
mov ebx, [ar2 + 8]
sub [ar1 + 8], ebx
@Exit:
pop ebx
end;
begin
//Fill arrays first!
SubQIntArray(Array1[0], Array2[0], length(Array1));
Я не эксперт по сборке, но я думаю, что следующее близко к оптимальному, если вы не принимаете во внимание инструкции SIMD или параллельную обработку, позже можно легко выполнить, передав части массива функции.
как
Thread1: SubArray (ar1[0], ar2[0], 50);
Thread2: SubArray (ar1[50], ar2[50], 50);
procedure SubArray(var Array1, Array2; const Length: Integer);
var
ap1, ap2 : PInteger;
i : Integer;
begin
ap1 := @Array1;
ap2 := @Array2;
i := Length;
while i > 0 do
begin
ap1^ := ap1^ - ap2^;
Inc(ap1);
Inc(ap2);
Dec(i);
end;
end;
// similar assembly version
procedure SubArrayEx(var Array1, Array2; const Length: Integer);
asm
// eax = @Array1
// edx = @Array2
// ecx = Length
// esi = temp register for array2^
push esi
cmp ecx, 0
jle @Exit
@Loop:
mov esi, [edx]
sub [eax], esi
add eax, 4
add edx, 4
dec ecx
jnz @Loop
@Exit:
pop esi
end;
procedure Test();
var
a1, a2 : array of Integer;
i : Integer;
begin
SetLength(a1, 3);
a1[0] := 3;
a1[1] := 1;
a1[2] := 2;
SetLength(a2, 3);
a2[0] := 4;
a2[1] := 21;
a2[2] := 2;
SubArray(a1[0], a2[0], Length(a1));
for i := 0 to Length(a1) - 1 do
Writeln(a1[i]);
Readln;
end;
Это не настоящий ответ на ваш вопрос, но я бы исследовал, если бы я мог сделать вычитание уже в какое-то время while заполнение массивов значениями. При желании я бы даже рассмотрел третий массив в памяти для хранения результата вычитания. В современных вычислениях "стоимость" памяти значительно ниже, чем "стоимость" времени, необходимого для выполнения дополнительного действия над памятью.
теоретически вы получите хотя бы небольшую производительность, когда вычитание может быть сделано, пока значения все еще находятся в регистрах или кэше процессора, но на практике вы можете наткнуться на несколько трюков, которые могут повысить производительность всего алгоритма.