Обмен данными между базами данных SQL
Я пытаюсь решить проблему, которая, на этот раз, я не создавал.
Я работаю в среде со многими веб-приложениями, поддерживаемыми различными базами данных на разных серверах.
каждая база данных довольно уникальна в своем дизайне и применении, но в каждой из них все еще остаются общие данные, которые я хотел бы абстрагировать. Каждая база данных, например, имеет таблицу поставщиков, таблицу пользователей и т. д...
Я хотел бы абстрагировать эти общие данные в один но все же пусть другие базы данных присоединяются к этим таблицам, даже имеют ключи для обеспечения ограничений и т. д... Я в среду в MSSQL.
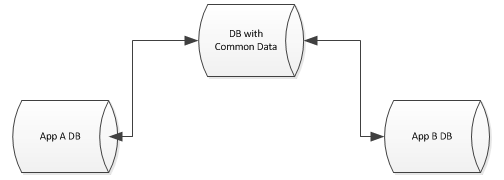
какие варианты? Как я это вижу, у меня есть следующие варианты:
- связанные серверы
- только для чтения Логинов, чтобы дать доступ к представлениям
что-нибудь еще рассмотреть?
5 ответов
есть много способов решить эту проблему. Я настоятельно рекомендую либо решения 1, 2 или 3 в зависимости от ваших бизнес-потребностей:
-
Репликация Транзакций: если общая база данных является записью учетной записи, и вы хотите предоставить только для чтения версии данных для отдельных приложений, то вы можете реплицировать основные таблицы, возможно, даже только основные столбцы таблиц, на каждый отдельный сервер. Одним из преимуществ этой подход заключается в том, что вы можете реплицировать столько баз данных подписчиков, сколько хотите. Это также означает, что вы можете настроить, какие таблицы и поля доступны подписчикам в зависимости от их потребностей. Поэтому, если одному приложению нужны пользовательские таблицы, а не таблицы поставщиков, вы подписываетесь только на пользовательские таблицы. Если другому нужны только таблицы поставщиков, а не пользовательские таблицы, можно подписаться только на таблицы поставщиков. Еще один плюс заключается в том, что репликация синхронизируется, и вы всегда можете повторно инициализировать подписка, если возникнет проблема.
Я использовал репликацию транзакций, чтобы вытеснить более 100 таблиц из хранилища данных для разделения нижестоящих приложений, которым необходим доступ к агрегированным данным из нескольких систем. Поскольку наше хранилище данных обновлялось ежечасно по расписанию из зеркальных и логарифмических источников данных, производственные приложения имели данные из многочисленных систем в пределах скользящего окна от 20 до 80 минут каждый час.
одноранговой репликация транзакций как тип публикации может быть лучше подходит для случая использования, который вы предоставили. Это может быть очень полезно, если вы хотите развернуть схему или репликацию изменений узла за узлом. Стандартная репликация транзакций имеет некоторые ограничения в этой области.
типы публикаций репликации моментальных снимков имеют большую задержку, чем публикации транзакций, но вы можете рассмотреть ее, если допустима степень задержки.
хотя вы упомянули Вы магазин Microsoft SQL Server, пожалуйста, имейте в виду, что другие СУБД имеют аналогичные технологии. Поскольку вы говорите о MS SQL Server конкретно, обратите внимание, что репликация транзакций также позволяет реплицироваться в базы данных Oracle. Так что если у вас есть несколько из них в вашей организации, это решение может работать.
недостатком использования репликации транзакций является то, что если вы центральный сервер идет вниз, вы можете начать испытывать задержку с данными в нижестоящих копиях реплицируемый объект. Если реплицированные объекты (статьи) действительно большие, и вам нужно повторно инициализировать таблицу, то это может занять очень много времени.
зеркала: если вы хотите сделать базу данных доступной в режиме реального времени на нижестоящих серверах, вы можете настроить до двух асинхронных зеркал. Я интегрировал данные с приложением CRM таким образом. Все чтения приходили из "соединения с зеркалом". Все записи были помещены в очередь сообщений который затем применил изменения к центральному производственному серверу. Недостатком этого подхода является то, что вы не можете создать более 2 асинхронных зеркал. Вы не хотите использовать синхронные зеркала для этой цели, если вы не планируете использовать зеркала для аварийного восстановления.
Системы Обмена Сообщениями: если вы ожидаете иметь многочисленные отдельные приложения, которые нуждаются в данных из одной центральной базы данных, то вы можете рассмотреть enterprise системы обмена сообщениями, такие как IBM Web Sphere, Microsoft BizTalk, Vitria, TIBCO и др. Эти приложения созданы специально для решения этой проблемы. Они, как правило, дорогостоящие и громоздкие в реализации и обслуживании, но они могут масштабироваться, если у вас есть глобально распределенные системы или десятки отдельных приложений, которые все должны обмениваться данными в той или иной степени.
-
Связанные Серверы: похоже, вы уже думали об этом. Вы можете предоставить данные через связанные серверы. Я не думаю, что это хорошее решение. Если вы действительно хотите пройти этот маршрут, подумайте о настройке асинхронного зеркала из центральной базы данных на другой сервер, а затем настройте связанные подключения сервера к зеркалу. Это по крайней мере уменьшит риск того, что запрос из веб-приложений вызовет блокировку или проблемы с производительностью Центральной производственной базы данных.
IMO, связанные серверы, как правило, являются опасным методом обмена данными для приложения. Этот подход по-прежнему рассматривает данные как гражданина второго класса в вашей базе данных. Это приводит к некоторым довольно плохим привычкам кодирования, особенно потому, что ваши разработчики могут работать на разных серверах на разных языках с разными методами подключения. Вы не знаете, если кто-то напишет по-настоящему henious запрос против ваших основных данных. Если вы установили стандарт, который требует нажатия полной копии общих данных на неосновной сервер, вам не нужно беспокоиться о независимо от того, пишет ли разработчик плохой код. По крайней мере, с точки зрения того, что их плохой код не будет jeapordize производительность других хорошо написанных систем.
есть много, много ресурсов, которые объясняют, почему использование связанных серверов может быть плохим в этом контексте. Неисчерпывающий перечень причин включает: (a)учетная запись, используемая для связанного сервера, должна иметь разрешения DBCC SHOW STATISTICS, иначе запросы не смогут использовать существующую статистику, (b) подсказки запроса не могут быть uesd, если они не представлены как OPENQUERY, (c) параметры не могут быть переданы при использовании с OPENQUERY, (d) сервер не имеет достаточной статистики о связанном сервере, следовательно, создает довольно ужасные планы запросов, (e) проблемы с сетевым подключением могут вызвать сбои, (f) любой из этих пяти вопросов производительности, и (g)страшная ошибка контекста SSPI при попытке проверки подлинности учетных данных Windows active directory в двойном прыжке сценарий. Связанные серверы могут быть полезны для некоторых конкретных сценариев, но создание доступа к центральной базе данных вокруг этой функции, хотя и технически возможно, не рекомендуется.
-
массовый процесс ETL: если высокая степень задержки приемлема для веб-приложений, то вы можете написать массовые процессы ETL с SSIS (много хороших ссылок в этом вопросе StackOverflow) которые выполняются заданиями агента SQL Server для перемещения данных между сервера. Существуют также другие альтернативные инструменты ETL, такие как Informatica, Pentaho и т. д. используй то, что лучше для тебя.
Это не хорошее решение, если вам нужна низкая степень задержки. Я использовал это решение при синхронизации с сторонним CRM-решением для полей, которые могут переносить высокую задержку. Для полей, которые не могли выдержать высокую задержку (основные данные создания учетной записи), мы полагались на создание дубликатов записей в CRM через вызовы веб-службы в точке генерация счета.
ночное резервное копирование и восстановление: Если ваши данные могут переносить высокую степень задержки (до дня) и периоды недоступности, вы можете создавать резервные копии и восстанавливать базу данных в разных средах. Это не очень хорошее решение для веб-приложений, которым требуется 100% время работы. Идея заключается в том, что вы берете базовую резервную копию, восстанавливаете ее до отдельного имени восстановления, а затем переименовываете исходную базу данных и новую, как только новая будет готова к использованию. Я видел, как это делается для некоторых внутренних веб-приложений, но я обычно не рекомендую этот подход. Это лучше подходит для более низкой среды разработки, а не для производственной среды.
Журнал Доставки Вторичных: вы можете настроить доставку журналов между основным и любым количеством второстепенных. Это похоже на ночной процесс резервного копирования и восстановления, за исключением того, что вы можете обновлять базу данных чаще. В одном случае это решение было использовано для предоставления данных из одной из наших основных основных систем нижестоящим пользователям путем переключения между двумя получателями доставки журналов. Был еще один сервер, который указывал на две базы данных и переключался между ними, когда новая была доступна. Я действительно ненавижу это решение, но один раз я видел эту реализацию, она отвечала потребностям бизнеса.
можно также использовать встроенную репликацию SQL Server между общим хранилищем данных и DBs приложений. По моему опыту, он хорошо подходит для двусторонней передачи данных, и в каждой БД есть экземпляр таблиц, позволяющий использовать внешние ключи (я не думаю, что FKs возможны через связанный сервер).
могут быть и другие варианты, но думаю, что вы правильный путь для оптимальный вариант С комбинацией связанных серверов и представлений. Это может быть так же просто, как создание новой базы данных, добавление двух связанных серверов, настройка разрешений и создание необходимого представления.
Если ваши цели abstract out this common data to a single database but still let the other databases join on these tables, even have keys to enforce constraints затем это решение должно работать нормально.
на нижней стороне вы можете столкнуться с проблемами производительности со связанными серверами, поэтому, если вы предвидите база данных получает много трафика, то вы можете посмотреть на самом деле перемещение данных с помощью методов, которые предложил дуг или mwebber.
Если вы идете по маршруту связанного сервера, я бы рекомендовал читать on OPENQUERY. Есть хорошая статья на OPENQUERY vs 4 часть идентификаторы здесь.
посмотри Microsoft Sync Framework. Вам придется написать приложение синхронизации, но это может дать вам необходимую гибкость.
Я думаю, что вы должны хорошо взглянуть на репликацию, как указано во многих ответах, особенно в среде с высоким TPS, или вы хотите это на многих таблицах. Тем не менее, я предложу некоторый код о том, как я достигаю ваших заявленных целей в некоторых из моих систем, используя связанные серверы, синонимы и ограничения проверки.
Я хотел бы абстрагировать эти общие данные в одну базу данных, но все же пусть другие базы данных присоединяются к этим таблицам, даже имеют ключи для обеспечения ограничений, и т. д.
Вы можете настроить вид или синоним в ваших базах данных в общую таблицу на связанном сервере (или другой локальной БД). Я предпочитаю синонимы, если бы представление было просто select * from table в любом случае.
синоним таблицы позволит вам запустить DML на удаленном элементе, если у вас есть разрешения.
на данный момент, однако, у вас не может быть внешнего ключа для вашего представления или синонима, но мы можем выполнить что-то подобное с проверкой ограничение.
давайте посмотрим код:
create synonym MyCentralTable for MyLinkedServer.MyCentralDB.dbo.MyCentralTable
go
create function dbo.MyLocalTableFkConstraint (
@PK int
)
returns bit
as begin
declare @retVal bit
select @retVal = case when exists (
select null from MyCentralTable where PK = @PK
) then 1 else 0 end
return @retVal
end
go
create table MyLocalTable (
FK int check (dbo.MyLocalTableFKConstraint(FK) = 1)
)
go
-- Will fail: -1 not in MyLinkedServer.MyRemoteDatabase.dbo.MyCentralTable
insert into MyLocalTable select -1
-- Will succeed: RI on a remote table w/o triggers
insert into MyLocalTable select FK from MyCentralTable
конечно, важно отметить, что вы не получите ошибку, если вы удалите ссылочную запись в центральной таблице.