Плохая производительность memcpy в Linux
недавно мы приобрели несколько новых серверов и испытываем низкую производительность memcpy. Производительность memcpy в 3 раза медленнее на серверах по сравнению с нашими ноутбуками.
Сервер Спецификаций
- шасси и Mobo: SUPER MICRO 1027GR-TRF
- процессор: 2x Intel Xeon E5-2680 @ 2.70 ГГц
- память: 8x 16GB DDR3 1600MHz
Edit: я также тестирую на другом сервере с немного более высокими характеристиками и видя те же результаты, что и вышеупомянутый сервер
Сервер 2 Спецификации
- шасси и Mobo: SUPER MICRO 10227GR-TRFT
- процессор: 2x Intel Xeon E5-2650 v2 @ 2.6 ГГц
- память: 8x 16GB DDR3 1866MHz
Ноутбук Технические Характеристики
- Шасси: Lenovo W530
- процессор: 1x Intel Core i7 i7-3720QM @ 2.6 ГГц
- память: 4X 4GB DDR3 1600МГц
Операционные Системы
$ cat /etc/redhat-release
Scientific Linux release 6.5 (Carbon)
$ uname -a
Linux r113 2.6.32-431.1.2.el6.x86_64 #1 SMP Thu Dec 12 13:59:19 CST 2013 x86_64 x86_64 x86_64 GNU/Linux
компилятор (на всех системах)
$ gcc --version
gcc (GCC) 4.6.1
также протестировано с gcc 4.8.2 на основе предложения от @stefan. Между компиляторами не было разницы в производительности.
Тестовый Код Тестовый код ниже-это консервированный тест для дублирования проблемы, которую я вижу в нашем производственном коде. Я знаю, что этот тест является упрощенным, но он смог использовать и определите нашу проблему. Код создает два буфера 1GB и memcpys между ними, синхронизируя вызов memcpy. Вы можете указать альтернативные размеры буфера в командной строке, используя: ./ big_memcpy_test [SIZE_BYTES]
#include <chrono>
#include <cstring>
#include <iostream>
#include <cstdint>
class Timer
{
public:
Timer()
: mStart(),
mStop()
{
update();
}
void update()
{
mStart = std::chrono::high_resolution_clock::now();
mStop = mStart;
}
double elapsedMs()
{
mStop = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds elapsed_ms =
std::chrono::duration_cast<std::chrono::milliseconds>(mStop - mStart);
return elapsed_ms.count();
}
private:
std::chrono::high_resolution_clock::time_point mStart;
std::chrono::high_resolution_clock::time_point mStop;
};
std::string formatBytes(std::uint64_t bytes)
{
static const int num_suffix = 5;
static const char* suffix[num_suffix] = { "B", "KB", "MB", "GB", "TB" };
double dbl_s_byte = bytes;
int i = 0;
for (; (int)(bytes / 1024.) > 0 && i < num_suffix;
++i, bytes /= 1024.)
{
dbl_s_byte = bytes / 1024.0;
}
const int buf_len = 64;
char buf[buf_len];
// use snprintf so there is no buffer overrun
int res = snprintf(buf, buf_len,"%0.2f%s", dbl_s_byte, suffix[i]);
// snprintf returns number of characters that would have been written if n had
// been sufficiently large, not counting the terminating null character.
// if an encoding error occurs, a negative number is returned.
if (res >= 0)
{
return std::string(buf);
}
return std::string();
}
void doMemmove(void* pDest, const void* pSource, std::size_t sizeBytes)
{
memmove(pDest, pSource, sizeBytes);
}
int main(int argc, char* argv[])
{
std::uint64_t SIZE_BYTES = 1073741824; // 1GB
if (argc > 1)
{
SIZE_BYTES = std::stoull(argv[1]);
std::cout << "Using buffer size from command line: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
else
{
std::cout << "To specify a custom buffer size: big_memcpy_test [SIZE_BYTES] n"
<< "Using built in buffer size: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
// big array to use for testing
char* p_big_array = NULL;
/////////////
// malloc
{
Timer timer;
p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
if (p_big_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " returned NULL!"
<< std::endl;
return 1;
}
std::cout << "malloc for " << formatBytes(SIZE_BYTES) << " took "
<< timer.elapsedMs() << "ms"
<< std::endl;
}
/////////////
// memset
{
Timer timer;
// set all data in p_big_array to 0
memset(p_big_array, 0xF, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memset for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
}
/////////////
// memcpy
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memcpy test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memcpy FROM p_big_array TO p_dest_array
Timer timer;
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memcpy for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
/////////////
// memmove
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memmove test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memmove FROM p_big_array TO p_dest_array
Timer timer;
// memmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
doMemmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memmove for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
// cleanup
free(p_big_array);
p_big_array = NULL;
return 0;
}
CMake файл для сборки
project(big_memcpy_test)
cmake_minimum_required(VERSION 2.4.0)
include_directories(${CMAKE_CURRENT_SOURCE_DIR})
# create verbose makefiles that show each command line as it is issued
set( CMAKE_VERBOSE_MAKEFILE ON CACHE BOOL "Verbose" FORCE )
# release mode
set( CMAKE_BUILD_TYPE Release )
# grab in CXXFLAGS environment variable and append C++11 and -Wall options
set( CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x -Wall -march=native -mtune=native" )
message( INFO "CMAKE_CXX_FLAGS = ${CMAKE_CXX_FLAGS}" )
# sources to build
set(big_memcpy_test_SRCS
main.cpp
)
# create an executable file named "big_memcpy_test" from
# the source files in the variable "big_memcpy_test_SRCS".
add_executable(big_memcpy_test ${big_memcpy_test_SRCS})
Результаты Теста
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 1
Laptop 2 | 0 | 180 | 120 | 1
Server 1 | 0 | 306 | 301 | 2
Server 2 | 0 | 352 | 325 | 2
как вы можете видеть memcpys и memsets на наших серверах намного медленнее, чем memcpys и memsets на нашем ноутбуки.
различные размеры буфера
я пробовал буферы от 100MB до 5GB все с аналогичными результатами (серверы медленнее, чем ноутбук)
Нюма сродство
я читал о людях, имеющих проблемы с производительностью с NUMA, поэтому я попытался установить сходство CPU и памяти с помощью numactl, но результаты остались прежними.
серверное оборудование NUMA
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 65501 MB
node 0 free: 62608 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 65536 MB
node 1 free: 63837 MB
node distances:
node 0 1
0: 10 21
1: 21 10
ноутбук NUMA Оборудование
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 16018 MB
node 0 free: 6622 MB
node distances:
node 0
0: 10
настройка сродства NUMA
$ numactl --cpunodebind=0 --membind=0 ./big_memcpy_test
любая помощь в разрешении этого очень ценится.
Edit: параметры GCC
на основе комментариев я попытался скомпилировать с различными параметрами GCC:
компиляция с-march и-mtune установлена в native
g++ -std=c++0x -Wall -march=native -mtune=native -O3 -DNDEBUG -o big_memcpy_test main.cpp
результат: точно такая же производительность (без улучшения)
компиляция с-O2 вместо - O3
g++ -std=c++0x -Wall -march=native -mtune=native -O2 -DNDEBUG -o big_memcpy_test main.cpp
результат: точно такая же производительность (без улучшения)
Edit: изменен memset для записи 0xF вместо 0, чтобы избежать нулевой страницы (@SteveCox)
нет улучшения при memsetting со значением, отличным от 0 (в этом случае используется 0xF).
Edit: результаты Cachebench
чтобы исключить, что моя тестовая программа слишком упрощена, я загрузил настоящую программу бенчмаркинга LLCacheBench (http://icl.cs.utk.edu/projects/llcbench/cachebench.html)
я построил эталон на каждой машине отдельно, чтобы избежать проблем с архитектурой. Ниже приведены мои результаты.
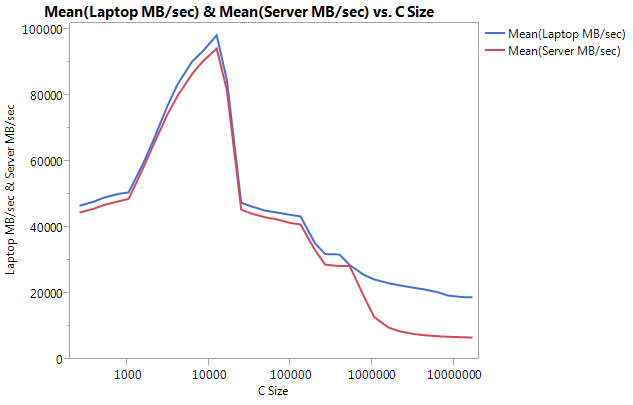
обратите внимание, что очень большая разница-это производительность при больших размерах буфера. Последний протестированный размер (16777216) выполнен при 18849.29 МБ/сек на ноутбуке и 6710.40 на сервере. Это примерно 3-кратная разница в производительности. Вы также можете заметить, что снижение производительности сервера намного круче, чем на ноутбуке.
Edit: memmove() на 2x быстрее, чем memcpy () на сервере
на основе некоторых экспериментов я попытался использовать memmove() вместо memcpy () в моем тестовом примере и нашел улучшение 2x на сервере. Memmove() на ноутбуке работает медленнее, чем memcpy (), но, как ни странно, работает с той же скоростью, что и memmove () на сервере. Это вызывает вопрос, почему memcpy так медленно?
обновленный код для тестирования memmove вместе с memcpy. Мне пришлось обернуть memmove () внутри функции, потому что если я оставил его встроенным, GCC оптимизировал его и выполнил точно так же, как memcpy () (я предполагаю, что gcc оптимизировал его для memcpy, потому что он знал, что местоположения не перекрываются).
Обновленные Результаты
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | memmove() | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 161 | 1
Laptop 2 | 0 | 180 | 120 | 160 | 1
Server 1 | 0 | 306 | 301 | 159 | 2
Server 2 | 0 | 352 | 325 | 159 | 2
Edit: Наивный Memcpy
на основе предложения от @Salgar я реализовал свою собственную наивную функцию memcpy и проверить его.
Наивный Источник Memcpy
void naiveMemcpy(void* pDest, const void* pSource, std::size_t sizeBytes)
{
char* p_dest = (char*)pDest;
const char* p_source = (const char*)pSource;
for (std::size_t i = 0; i < sizeBytes; ++i)
{
*p_dest++ = *p_source++;
}
}
наивные результаты Memcpy по сравнению с memcpy ()
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop 1 | 113 | 161 | 160
Server 1 | 301 | 159 | 159
Server 2 | 325 | 159 | 159
Edit: Вывод Сборки
простой источник memcpy
#include <cstring>
#include <cstdlib>
int main(int argc, char* argv[])
{
size_t SIZE_BYTES = 1073741824; // 1GB
char* p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
char* p_dest_array = (char*)malloc(SIZE_BYTES * sizeof(char));
memset(p_big_array, 0xA, SIZE_BYTES * sizeof(char));
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
free(p_dest_array);
free(p_big_array);
return 0;
}
вывод сборки: это то же самое как на сервере, так и на ноутбуке. Я экономлю место и не приклеиваю оба.
.file "main_memcpy.cpp"
.section .text.startup,"ax",@progbits
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB25:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movl 73741824, %edi
pushq %rbx
.cfi_def_cfa_offset 24
.cfi_offset 3, -24
subq , %rsp
.cfi_def_cfa_offset 32
call malloc
movl 73741824, %edi
movq %rax, %rbx
call malloc
movl 73741824, %edx
movq %rax, %rbp
movl , %esi
movq %rbx, %rdi
call memset
movl 73741824, %edx
movl , %esi
movq %rbp, %rdi
call memset
movl 73741824, %edx
movq %rbx, %rsi
movq %rbp, %rdi
call memcpy
movq %rbp, %rdi
call free
movq %rbx, %rdi
call free
addq , %rsp
.cfi_def_cfa_offset 24
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 16
popq %rbp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE25:
.size main, .-main
.ident "GCC: (GNU) 4.6.1"
.section .note.GNU-stack,"",@progbits
прогресс!!!! asmlib
на основе предложения от @tbenson я попытался бежать с asmlib версия memcpy. Мои результаты изначально были плохими, но после изменения SetMemcpyCacheLimit () на 1GB (размер моего буфера) я работал со скоростью наравне с моим наивным циклом for!
плохая новость заключается в том, что версия asmlib memmove медленнее, чем версия glibc, теперь она работает на отметке 300ms (наравне с версией glibc memcpy). Странно то, что на ноутбуке, когда я SetMemcpyCacheLimit() на большое количество больно спектакль...
в результатах ниже строк, отмеченных SetCache, SetMemcpyCacheLimit установлен в 1073741824. Результаты без SetCache не вызывают SetMemcpyCacheLimit ()
результаты с использованием функций из asmlib:
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop | 136 | 132 | 161
Laptop SetCache | 182 | 137 | 161
Server 1 | 305 | 302 | 164
Server 1 SetCache | 162 | 303 | 164
Server 2 | 300 | 299 | 166
Server 2 SetCache | 166 | 301 | 166
начало склоняться к проблеме кэша, но что может вызвать это?
7 ответов
[Я бы сделал это замечание, но у меня недостаточно репутации для этого.]
у меня есть аналогичная система и вижу аналогичные результаты, но могу добавить несколько точек данных:
- если вы измените направление вашего наивного
memcpy(т. е. преобразовать в*p_dest-- = *p_src--), то вы можете получить гораздо худшую производительность, чем для прямого направления (~637 мс для меня). Вmemcpy()в glibc 2.12, который выявил несколько ошибок для вызоваmemcpyна перекрывающиеся буферы (http://lwn.net/Articles/414467/) и я считаю, что проблема была вызвана переключением на версиюmemcpy, который работает в обратном направлении. Таким образом, обратная и прямая копии могут объяснитьmemcpy()/memmove()разрыв. - кажется, лучше не использовать нестационарные магазины. Многие оптимизированы
memcpy()реализации переключаются на нестационарные хранилища (которые не кэшируются) для больших буферов (т. е. больше, чем кэш последнего уровня). Я протестировал версию memcpy Агнера Фога (http://www.agner.org/optimize/#asmlib) и обнаружил, что это примерно такая же скорость, как и версия вglibc. Однако,asmlibимеет функцию (SetMemcpyCacheLimit), что позволяет установить порог, выше которого используются нестационарные магазины. Установка этого ограничения на 8GiB (или просто больше, чем буфер 1 GiB), чтобы избежать нетрадиционных хранилищ, удвоила производительность в моем случае (время до 176 МС). Конечно, это только соответствовало наивной производительности в прямом направлении, поэтому это не так звездный. - BIOS в этих системах позволяет включать/отключать четыре различных аппаратных Prefetcher (MLC Streamer Prefetcher, MLC Spatial Prefetcher, DCU Streamer Prefetcher и DCU IP Prefetcher). Я попытался отключить каждый, но это в лучшем случае поддерживало четность производительности и снижало производительность для некоторых настроек.
- отключение режима работы средней мощности (RAPL) DRAM не влияет.
- у меня есть доступ к другим системам Supermicro используете Fedora 19 (в glibc 2.17). С помощью платы Supermicro X9DRG-HF, Fedora 19 и процессоров Xeon E5-2670 я вижу аналогичную производительность, как указано выше. На плате одного сокета Supermicro X10SLM-F под управлением Xeon E3-1275 v3 (Haswell) и Fedora 19 я вижу 9.6 GB/s для
memcpy(104ms). ОЗУ в системе Haswell-DDR3-1600 (как и в других системах).
обновления
- я установил управление мощностью процессора на максимальную производительность и отключил гиперпоточность в BIOS. На основе
/proc/cpuinfo, ядра затем были синхронизированы на 3 ГГц. Однако это странно снизило производительность памяти примерно на 10%. - memtest86+ 4.10 сообщает о пропускной способности основной памяти 9091 МБ/ с. Я не мог найти, соответствует ли это чтению, записи или копированию.
- на поток benchmark отчеты 13422 МБ / с для копирования, но они считают байты как прочитанными, так и написанными, так что соответствует ~6.5 ГБ/С, если мы хотим сравнить с вышеизложенным результаты.
Это выглядит нормально для меня.
управление 8x16gb ECC Memory sticks с двумя процессорами-гораздо более жесткая работа, чем один процессор с 2x2GB. Ваши палочки 16GB являются двухсторонней памятью + они могут иметь буферы + ECC (даже отключены на уровне материнской платы)... все это делает путь данных к ОЗУ намного длиннее. У вас также есть 2 процессора, разделяющих ОЗУ, и даже если вы ничего не делаете на другом процессоре, всегда мало доступа к памяти. Переключение этих данных требует дополнительного времени. Просто посмотрите на огромная производительность потеряна на ПК, которые разделяют некоторую ОЗУ с графической картой.
еще твой Северс действительно мощный datapumps. Я не уверен, что дублирование 1GB происходит очень часто в реальном программном обеспечении, но я уверен, что ваши 128GBs намного быстрее, чем любой жесткий диск, даже лучший SSD, и именно здесь вы можете воспользоваться своими серверами. Выполнение того же теста с 3GB приведет к поджогу вашего ноутбука.
Это выглядит как идеальный пример того, как архитектура, основанная на товарное оборудование может быть гораздо более эффективным, чем большие серверы. Сколько потребительских ПК можно позволить себе на деньги, потраченные на эти большие серверы ?
Спасибо за ваш очень подробный вопрос.
EDIT: (мне потребовалось так много времени, чтобы написать этот ответ, что я пропустил часть графика.)
Я думаю, что проблема о том, где хранятся данные. Можете ли вы сравнить это:
- тест один : выделите два смежных блока 500MB ram и копирование с одного на другой (что вы уже сделали)
- тест два: выделите 20 (или более) блоков памяти 500 МБ и скопируйте от первого до последнего, чтобы они были далеко друг от друга (даже если вы не можете быть уверены в их реальном положении).
таким образом, вы увидите, как контроллер памяти обрабатывает блоки памяти вдали друг от друга. Я думаю, что ваши данные помещаются в разные зоны памяти, и в какой-то момент требуется операция переключения путь данных для разговора с одной зоной, а затем с другой (есть такая проблема с двухсторонней памятью).
кроме того, вы гарантируете, что поток привязан к одному процессору ?
EDIT 2:
существует несколько видов разделителей "зон" для памяти. Нума-один из них, но не единственный. Например, двухсторонние палочки требуют, чтобы флаг обращался к одной или другой стороне. Посмотрите на свой график, как производительность ухудшается с большим куском памяти даже на ноутбук (у которого нет NUMA). Я не уверен в этом, но memcpy может использовать аппаратную функцию для копирования ОЗУ (своего рода DMA), и этот чип должен иметь меньше кэша, чем ваш процессор, это может объяснить, почему тупая копия с процессором быстрее, чем memcpy.
возможно, что некоторые улучшения процессора в вашем ноутбуке на базе IvyBridge способствуют этому увеличению по сравнению с серверами на базе SandyBridge.
страница пересечения Prefetch - ваш ноутбук процессор будет prefetch впереди следующей линейной страницы, когда вы достигнете конца текущего, экономя вам неприятный TLB пропустить каждый раз. Чтобы попытаться смягчить это, попробуйте создать код сервера для страниц 2M / 1G.
схемы замены кэша также, похоже, были улучшены (см. интересное обратное проектирование здесь). Если этот процессор действительно использует динамическую политику вставки, он легко предотвратит попытку копирования данных в кэш последнего уровня (который он не может эффективно использовать из-за размера) и сохранит место для другого полезного кэширования, такого как код, стек, данные таблицы страниц и т. д..). Чтобы проверить это, вы можете попробовать перестроить свою наивную реализацию, используя потоковые нагрузки / магазины (
movntdqили аналогичных, вы также можете использовать встроенные ССЗ для этого). Эта возможность может объяснить внезапное падение размеров больших наборов данных.Я считаю, что некоторые улучшения также были сделаны со Строковой копией (здесь), он может или не может применяться здесь, в зависимости от того, как выглядит ваш код сборки. Вы можете попробовать бенчмаркинг с Dhrystone чтобы проверить, есть ли врожденная разница. Это также может объяснить разницу между memcpy и memmove языка.
Если бы вы могли получить сервер на основе IvyBridge или ноутбук Sandy-Bridge, было бы проще всего протестировать все это вместе.
Я изменил бенчмарк для использования таймера nsec в Linux и нашел аналогичные вариации на разных процессорах, все с одинаковой памятью. Все работает RHEL 6. Числа согласованы в нескольких запусках.
Sandy Bridge E5-2648L v2 @ 1.90GHz, HT enabled, L2/L3 256K/20M, 16 GB ECC
malloc for 1073741824 took 47us
memset for 1073741824 took 643841us
memcpy for 1073741824 took 486591us
Westmere E5645 @2.40 GHz, HT not enabled, dual 6-core, L2/L3 256K/12M, 12 GB ECC
malloc for 1073741824 took 54us
memset for 1073741824 took 789656us
memcpy for 1073741824 took 339707us
Jasper Forest C5549 @ 2.53GHz, HT enabled, dual quad-core, L2 256K/8M, 12 GB ECC
malloc for 1073741824 took 126us
memset for 1073741824 took 280107us
memcpy for 1073741824 took 272370us
вот результаты с встроенным кодом C-O3
Sandy Bridge E5-2648L v2 @ 1.90GHz, HT enabled, 256K/20M, 16 GB
malloc for 1 GB took 46 us
memset for 1 GB took 478722 us
memcpy for 1 GB took 262547 us
Westmere E5645 @2.40 GHz, HT not enabled, dual 6-core, 256K/12M, 12 GB
malloc for 1 GB took 53 us
memset for 1 GB took 681733 us
memcpy for 1 GB took 258147 us
Jasper Forest C5549 @ 2.53GHz, HT enabled, dual quad-core, 256K/8M, 12 GB
malloc for 1 GB took 67 us
memset for 1 GB took 254544 us
memcpy for 1 GB took 255658 us
для этого я также попытался сделать встроенный memcpy 8 байтов за раз. На этих процессорах Intel это не имело заметной разницы. Кэш объединяет все байтовые операции в минимальное количество операций памяти. Я подозреваю, что код библиотеки gcc пытается быть слишком умным.
на вопрос уже ответили выше, но в любом случае, вот реализация с использованием AVX, которая должна быть быстрее для больших копий, если это то, о чем вы беспокоитесь:
#define ALIGN(ptr, align) (((ptr) + (align) - 1) & ~((align) - 1))
void *memcpy_avx(void *dest, const void *src, size_t n)
{
char * d = static_cast<char*>(dest);
const char * s = static_cast<const char*>(src);
/* fall back to memcpy() if misaligned */
if ((reinterpret_cast<uintptr_t>(d) & 31) != (reinterpret_cast<uintptr_t>(s) & 31))
return memcpy(d, s, n);
if (reinterpret_cast<uintptr_t>(d) & 31) {
uintptr_t header_bytes = 32 - (reinterpret_cast<uintptr_t>(d) & 31);
assert(header_bytes < 32);
memcpy(d, s, min(header_bytes, n));
d = reinterpret_cast<char *>(ALIGN(reinterpret_cast<uintptr_t>(d), 32));
s = reinterpret_cast<char *>(ALIGN(reinterpret_cast<uintptr_t>(s), 32));
n -= min(header_bytes, n);
}
for (; n >= 64; s += 64, d += 64, n -= 64) {
__m256i *dest_cacheline = (__m256i *)d;
__m256i *src_cacheline = (__m256i *)s;
__m256i temp1 = _mm256_stream_load_si256(src_cacheline + 0);
__m256i temp2 = _mm256_stream_load_si256(src_cacheline + 1);
_mm256_stream_si256(dest_cacheline + 0, temp1);
_mm256_stream_si256(dest_cacheline + 1, temp2);
}
if (n > 0)
memcpy(d, s, n);
return dest;
}
цифры имеют смысл для меня. На самом деле здесь есть два вопроса, и я отвечу на оба.
во-первых, нам нужно иметь ментальную модель того, насколько велика1 передача памяти работает на чем-то вроде современного процессора Intel. Описание это примерное и детали могут несколько измениться от архитектуры к архитектуре, но идеи высокого уровня довольно постоянны.
- когда нагрузка пропускает в
L1кэш данных, а буфер строку выделяется, который будет отслеживать запрос miss, пока он не будет заполнен. Это может быть в течение короткого времени (дюжина циклов или около того), если он попадает вL2кэш или намного дольше (100+ наносекунд), если он пропускает весь путь до DRAM. - существует ограниченное количество этих линейных буферов на1, и как только они будут заполнены, дальнейшие промахи будут останавливаться в ожидании одного.
- кроме этих используемых буферов заполнения для спрос3 loads / stores существуют дополнительные буферы для перемещения памяти между DRAM и L2 и кэшами нижнего уровня, используемыми предварительной выборкой.
-
сама подсистема памяти максимальный предел пропускной способности, который вы найдете удобно перечислены на ARK. Например, 3720QM в ноутбуке Lenovo показывает предел 25.6 ГБ. Этот предел в основном является продуктом эффективной частоты (
1600 Mhz) раз 8 байт (64-бит) на передачу раз количество каналов (2):1600 * 8 * 2 = 25.6 GB/s. Серверный чип на руке имеет пиковую пропускную способность 51.2 ГБ/с, на сокет, для общей пропускной способности системы ~102 ГБ / с.в отличие от других функций процессора, часто есть только возможные теоретические номера пропускной способности во всем разнообразии чипов, так как это зависит только от отмеченных значений, которые часто одинаковы во многих разные микросхемы и даже разные архитектуры. Это нереалистичный ожидайте, что DRAM доставит точно теоретическую скорость (из-за различных проблемы низкого уровня, немного обсуждались здесь), но вы можете часто получать около 90% или более.
таким образом, основным следствием (1) является то, что вы можете рассматривать пропуски в ОЗУ как своего рода систему ответа на запрос. Промах на драм выделяет заполнить буфер и буфер освобождается, когда запрос вернется. Есть только 10 из этих буферов, на CPU, для спроса удар, который ставит строгое ограничение на пропускной способности памяти спроса один процессор может генерировать, в зависимости от его задержки.
например, давайте скажем ваш E5-2680 имеет задержку для DRAM 80ns. Каждый запрос приносит 64-байтовую строку кэша, поэтому вы просто выдали запросы последовательно DRAM, вы ожидаете пропускную способность ничтожного 64 bytes / 80 ns = 0.8 GB/s, и вы бы снова разрезали это пополам (по крайней мере), чтобы получить memcpy рисунок, так как он должен читать и написать. К счастью, вы могут ли ваши 10 буферов заполнения строк, чтобы вы могли перекрывать 10 одновременных запросов к памяти и увеличивать пропускную способность в 10 раз, что приводит к теоретической пропускной способности 8 Гбит / с.
если вы хотите углубиться в еще больше деталей,этой теме в значительной степени чистое золото. Вы найдете, что факты и цифры из Джон Маккалпин, он же " Dr Bandwidth будет общей темой ниже.
Итак, давайте перейдем к деталям и ответим на два вопроса...
почему memcpy намного медленнее, чем memmove или ручная копия на сервере?
вы показали, что вы ноутбуки системы делают memcpy benchmark в о 120 мс, в то время как серверные части принимают вокруг 300 мс. Вы также показали, что эта медлительность в основном не является фундаментальной, так как вы смогли использовать memmove и ваш ручной прокат memcpy (далее,hrm) для достижения времени около 160 МС, гораздо ближе (но еще медленнее, чем) производительность ноутбука.
мы уже показали выше, что для одного ядра пропускная способность ограничена общим доступным параллелизмом и задержкой, а не пропускной способностью DRAM. Мы ожидаем, что серверные части могут иметь более длительную задержку, но не 300 / 120 = 2.5x больше!
ответ лежит в streaming (он же non-temporal) магазины. Версия libc memcpy вы используете использует их, но memmove нет. Вы подтвердили это ваш "наивный" memcpy который также не использует их, а также мою настройку asmlib как использовать потоковые магазины (медленно), так и не (быстро).
потоковые магазины больно один процессор номера, так:
- (A) они предотвращают предварительную выборку строк, которые будут сохранены в кэше, что позволяет увеличить параллелизм, поскольку оборудование предварительной выборки имеет другие выделенные буферы за пределами 10 заполнить буферы что нагрузка требования / магазины используют.
- (B) известно, что E5-2680 особенно для потокового магазинах.
как лучше объяснить цитаты из Иоанна McCalpin в вышеописанных нить. На тему эффективности предварительной выборки и потоковых магазинов он говорит::
С" обычными " магазинами, prefetcher оборудования L2 может принести линии внутри продвижение и сокращение время заполнения буфера заняты, таким образом, увеличение устойчивой полосы пропускания. С другой стороны, с streaming (Cache-bypassing) хранит, записи буфера заполнения строки для магазины заняты в течение полного времени, необходимого для передачи данных контроллер DRAM. В этом случае нагрузки может быть ускорено аппаратная предварительная выборка, но магазины не могут, поэтому вы получаете некоторое ускорение, но не так много, как вы бы получили, если бы и грузы, и магазины были ускоренный.
... а затем, по-видимому, гораздо более длительная задержка для потоковых магазинов на E5,он говорит::
более простой "uncore" Xeon E3 может привести к значительному снижению Заполнение буфера строки для потоковых магазинов. Xeon E5 имеет гораздо более сложная структура кольца для навигации, чтобы передать потоковое хранение данных из основных буферов в контроллеры памяти, поэтому заполняемость может отличаются большим коэффициентом, чем память (read) задержка.
в частности, доктор Маккалпин измерил замедление ~1.8 x для E5 по сравнению с чипом с" клиентом " uncore, но замедление 2.5 x отчеты OP согласуется с тем, что, поскольку оценка 1.8 x сообщается для STREAM TRIAD, которая имеет соотношение нагрузок 2:1:магазины, в то время как memcpy находится в 1: 1, и магазины являются проблемной частью.
это не делает потоковую передачу плохой вещью-по сути, вы обмен латентности на меньшее общее потребление полосы пропускания. Вы получаете меньшую пропускную способность, потому что вы ограничены параллелизмом при использовании одного ядра, но вы избегаете всего трафика чтения для владения, поэтому вы, вероятно, увидите (небольшое) преимущество, если вы запустите тест одновременно на всех ядрах.
до сих пор не будучи артефактом вашей конфигурации программного или аппаратного обеспечения, точно такие же замедления были сообщены другими пользователями с тем же процессором.
почему сервер часть еще медленнее при использовании обычных магазинах?
даже после исправления проблемы с нестационарным магазином вы еще видя примерно в 160 / 120 = ~1.33x замедление на серверной части. Что происходит?
ну, это распространенное заблуждение, что серверные процессоры быстрее во всех отношениях быстрее или, по крайней мере, равны своим клиентским коллегам. Это просто неправда - то, за что вы платите (часто по $ 2,000 за чип или около того) на серверных частях, в основном (a) больше ядра (b) больше каналов памяти (c) поддержка более полной оперативной памяти (d) поддержка функций "enterprise-ish", таких как ECC, функции вирутализации и т. д.5.
на самом деле, с задержкой, серверные части обычно только равны или медленнее для своего клиента4 запасные части. Когда дело доходит до задержки памяти, это особенно верно, потому что:
- серверные части имеют более масштабируемый, но сложный "uncore", который часто должен поддерживать гораздо больше ядер и, следовательно, путь к раму длиннее.
- серверные части поддерживают больше ОЗУ (100 ГБ или несколько ТБ), что часто требует электрические предохранители поддержать такое большое количество.
- как и в случае OP, серверные части обычно имеют несколько сокетов, что добавляет проблемы когерентности кросс-сокетов к пути памяти.
таким образом, типично, что серверные части имеют задержку от 40% до 60% дольше, чем клиентские части. Для E5 вы, вероятно, находим, что ~80 НС-это обычная задержка к ОЗУ, в то время как клиентские части ближе к 50 НС.
таким образом, все, что ограничено задержкой RAM, будет работать медленнее на серверных частях, и, как оказалось,memcpy на одном ядре задержка ограничена. это сбивает с толку, потому что memcpy кажется как измерение полосы пропускания, верно? Хорошо, как описано выше, одно ядро не имеет достаточных ресурсов для хранения достаточного количества запросов на ОЗУ в полете время, чтобы приблизиться к полосе пропускания ОЗУ6, так что производительность напрямую зависит от задержки.
клиентские чипы, с другой стороны, имеют как меньшую задержку, так и меньшую пропускную способность, поэтому одно ядро намного ближе к насыщению полосы пропускания (часто именно поэтому потоковые магазины являются большой победой на клиентских частях - когда даже одно ядро может приблизиться к полосе пропускания ОЗУ, 50% - ное сокращение полосы пропускания, которое предлагает потоковые магазины, помогает много.
ссылки
есть много хороших источников, чтобы узнать больше об этом материале, вот пара.
- подробное описание компонентов задержки памяти
-
много результатов задержки памяти через процессоры новые и старые (см.
MemLatX86иNewMemLat) ссылки - подробный анализ задержек памяти Sandy Bridge (и Opteron) - почти такой же обломок OP использующий.
1 By большой я просто имею в виду несколько больше, чем LLC. Для копий, которые вписываются в LLC (или любой более высокий уровень кэша), поведение очень отличается. ОПС llcachebench график показывает, что на самом деле отклонение производительности начинается только тогда, когда буферы начинают превышать размер LLC.
2 в частности, количество буфера заполнения и по-видимому, постоянная при 10 в течение нескольких поколений, включая архитектуры, упомянутые в этом вопросе.
3 когда мы говорим спрос здесь мы имеем в виду, что он связан с явной загрузкой/хранением в коде, а не с тем, что он вводится предварительной выборкой.
4 когда я говорю о сервер здесь, я имею в виду процессор с сервер uncore. Это в значительной степени означает серию E5, как E3 серия вообще использует клиент uncore.
5 в будущем, похоже, вы можете добавить "расширения набора инструкций" в этот список, так как кажется, что AVX-512 появится только на серверных частях Skylake.
6 Per маленький закон при задержке 80 НС нам понадобится (51.2 B/ns * 80 ns) == 4096 bytes или 64 строки кэша в полете в любое время, чтобы достичь максимальной пропускной способности, но одно ядро обеспечивает менее 20.
Спецификации Сервера 1
- процессор: 2x Intel Xeon E5-2680 @ 2.70 ГГц
Сервер 2 Спецификации
- процессор: 2x Intel Xeon E5-2650 v2 @ 2.6 ГГц
согласно Intel ARK, оба E5-2650 и E5-2680 имеют расширение AVX.
CMake файл для сборки
это часть вашей проблемы. С CMake выбирает для вас довольно плохие флаги. Вы можете подтвердить это, запустив make VERBOSE=1.
вы должны добавить как -march=native и -O3 на CFLAGS и CXXFLAGS. Вы, вероятно, увидите резкое увеличение производительности. Он должен задействовать расширения AVX. Без -march=XXX, вы эффективно получаете минимальную машину i686 или x86_64. Без -O3, вам не заниматься векторизациям ССЗ.
Я не уверен, что GCC 4.6 способен на AVX (и друзей, таких как BMI). Я знаю GCC 4.8 или 4.9 способен, потому что мне пришлось выследить ошибку выравнивания, которая вызывала segfault, когда GCC аутсорсинг memcpy и memset в блок MMX. AVX и AVX2 позволяют CPU работать на 16-байтовых и 32-байтовых блоках данных одновременно.
если GCC отсутствует возможность отправки выровненных данных в блок MMX, может отсутствовать тот факт, что данные выровнены. Если ваши данные выровнены по 16 байтам, вы можете попробовать рассказать GCC, чтобы он знал, как работать с блоками fat. Для этого см. GCC __builtin_assume_aligned. Также смотрите такие вопросы, как как сказать GCC, что аргумент указателя всегда выровнен по двум словам?
это выглядит немного подозрительно из-за void*. Это своего рода выбрасывание информации о указателе. Вы, вероятно, должны сохранить информацию:
void doMemmove(void* pDest, const void* pSource, std::size_t sizeBytes)
{
memmove(pDest, pSource, sizeBytes);
}
может, что-то вроде следующего:
template <typename T>
void doMemmove(T* pDest, const T* pSource, std::size_t count)
{
memmove(pDest, pSource, count*sizeof(T));
}
другое предложение-использовать new, и прекратить использовать malloc. Его программа на C++ и GCC может сделать некоторые предположения о new что он не может сделать о malloc. Я считаю, что некоторые из предположений подробно описаны на странице опций GCC для встроенных модулей.
еще одно предложение-использовать кучу. Его всегда 16 байт на типичных современных систем. GCC должен распознать, что он может разгрузиться на блок MMX, когда указатель из кучи задействован (без потенциала void* и malloc вопросы).
наконец, некоторое время Clang не использовал собственные расширения CPU при использовании -march=native. См., например, Ubuntu выпуск 1616723, Clang 3.4 только рекламирует SSE2, Ubuntu выпуск 1616723, Clang 3.5 только рекламирует SSE2 и Ubuntu выпуск 1616723, Clang 3.6 только рекламирует SSE2.