Почему бы мне не использовать "венгерскую нотацию"?
Я знаю, что венгерский означает-предоставление информации о переменной, параметре или типе в качестве префикса к ее имени. Все, кажется, бешено против этого, хотя в некоторых случаях это кажется хорошей идеей. Если я чувствую, что полезная информация передается, почему бы мне не поместить ее прямо там, где она доступна?
Читайте также: используют ли люди венгерские соглашения об именах в реальном мире?
30 ответов
большинство людей используют венгерскую нотацию неправильно и получают неправильные результаты.
прочитайте эту превосходную статью Джоэла Спольски:Неправильный Код Выглядит Неправильно.
короче говоря, венгерская нотация, где вы префикс ваших имен переменных с их type (string) (Systems Hungarian) плохо, потому что это бесполезно.
венгерская нотация, как это было задумано ее автором, где вы префикс имя переменной с его kind (через Иоиля пример: безопасная строка или небезопасная строка), так называемые приложения венгерский имеет свое использование и по-прежнему ценен.
Джоэл ошибается, и вот почему.
эта информация о "приложении", о которой он говорит должно быть закодировано в системе типов. Вы не должны зависеть от перелистывания имен переменных, чтобы убедиться, что вы не передаете небезопасные данные функциям, требующим безопасных данных. Вы должны сделать это ошибкой типа, так что это невозможно сделать это. Любые небезопасные данные должны иметь тип, помеченный как небезопасный, так что они просто не могут быть переданы безопасной функции. Конвертировать из небезопасно для безопасности должна потребоваться обработка с какой-то функцией дезинфекции.
strong typedef std::string unsafe_string; ввести новый типunsafe_string это не может быть преобразовано в строку std:: (и поэтому может участвовать в разрешении перегрузки и т. д. так далее. тогда нам не понадобятся глупые приставки.
Итак, центральное утверждение, что венгерский язык для вещей, которые не являются типами, неверно. Он используется для ввода информации. Более богатая информация типа, чем традиционная информация типа C, конечно; это информация типа, которая кодирует какой-то вид семантическая деталь, указывающая назначение объектов. Но это все еще информация типа, и правильным решением всегда было кодировать ее в систему типов. Кодирование его в систему типов-это далеко не лучший способ получить правильную проверку и соблюдение правил. Переменные имена просто не сокращает горчицу.
другими словами, целью не должно быть "сделать неправильный код неправильным для разработчика". Это должно быть "make wrong code look wrong к компилятор".
Я думаю, что это массово забивает исходный код.
Он также не получает вас много на строго типизированном языке. Если вы делаете какую-либо форму несоответствия типов tomfoolery, компилятор расскажет вам об этом.
венгерская нотация имеет смысл только в языках без пользовательских типов. В современном функциональном или OO-языке вы бы кодировали информацию о" виде " значения в тип данных или класс, а не в имя переменной.
несколько ответов ссылка Joels article. Обратите внимание, однако, что его пример находится в VBScript, который не поддерживал пользовательские классы (по крайней мере, долгое время). На языке с пользовательскими типами, вы бы решите ту же проблему, создав тип HtmlEncodedString, а затем позвольте методу Write принять только это. В статически типизированном языке компилятор поймает любую кодировку-ошибки, в динамически типизированном вы получите исключение во время выполнения , но в любом случае вы защищены от написания некодированных строк. Венгерские обозначения просто превращают программиста в человека, проверяющего тип, с такой работой, которая обычно лучше обрабатывается программным обеспечением.
Джоэл отличает между "systems hungarian" и "apps hungarian", где "systems hungarian" кодирует встроенные типы, такие как int, float и т. д., А "apps hungarian" кодирует "виды", что является метаинформацией более высокого уровня о переменной вне типа машины, на OO или современном функциональном языке вы можете создавать пользовательские типы, таким образом, в этом смысле нет различия между типом и "видом" - оба могут быть представлены системой типов - и" приложения "венгерский так же избыточны, как" системы" венгерский.
Итак, чтобы ответить на ваш вопрос:венгерский систем было бы полезно только в небезопасном, слабо типизированном языке, где, например, присвоение значения float переменной int приведет к сбою системы. Венгерская нотация была специально изобретена в шестидесятых годах для использования в нуждающийся в представлении, довольно низкоуровневый язык, который вообще не проверял тип. Я не думаю, что какой-либо язык в общем использовании сегодня имеет эту проблему, но нотация жила как своего рода культ карго программирования.
приложения венгерские будет иметь смысл, если вы работаете с языком без определенных пользователем типов, таких как legacy VBScript или ранние версии VB. Возможно также ранние версии Perl и PHP. Опять же, использование его в современном языке-это чистый культ груза.
на любом другом языке венгерский просто уродливый, избыточный и хрупкий. Он повторяет информацию, уже известную из системы типов, и вы не должны повторять себя!--6-->. Используйте описательное имя для переменной, описывающей намерение данного конкретного экземпляра типа. Используйте систему типов для кодирования инвариантов и метаинформации о" видах "или" классах " переменных-т. е. типы.
общий смысл статьи Joels - иметь неправильный код выглядеть неправильно - это очень хороший принцип. Однако еще лучшая защита от ошибок - когда это вообще возможно - имеет неправильный код, который будет обнаружен автоматически компилятором.
Я всегда использую венгерскую нотацию для всех моих проектов. Я считаю, что это очень полезно, когда я имею дело с 100s разных имен идентификаторов.
например, когда я вызываю функцию, требующую строки, я могу ввести " s "и нажать control-space, и моя IDE покажет мне точно имена переменных с префиксом "s".
еще одно преимущество, когда я префикс u для unsigned и i для подписанных ints, я сразу вижу, где я смешиваю подписанный и неподписанный в потенциально опасном пути.
Я не могу вспомнить количество раз, когда в огромной кодовой базе 75000 строк ошибки были вызваны (мной и другими тоже) из-за именования локальных переменных такими же, как существующие переменные-члены этого класса. С тех пор я всегда префикс членов С 'мы'
Это вопрос вкуса и опыта. Не стучите, пока не попробуете.
вы забываете причину номер один, чтобы включить эту информацию. Это не имеет ничего общего с вами, программист. Это имеет отношение к человеку, который приходит по дороге через 2 или 3 года после того, как вы покидаете компанию, который должен прочитать этот материал.
да, IDE быстро определит типы для вас. Однако, когда вы читаете некоторые длинные пакеты кода "бизнес-правил", приятно не останавливаться на каждой переменной, чтобы узнать, какой это тип. Когда я вижу такие вещи, как strUserID, intProduct или guiProductID, он делает для много легче 'нарастить' время.
Я согласен, что MS зашла слишком далеко с некоторыми из их соглашений об именах - я классифицирую это в куче "слишком много хорошего".
соглашения об именах-это хорошие вещи, если вы придерживаетесь их. Я прошел через достаточно старый код, который заставил меня постоянно возвращаться, чтобы посмотреть на определения для стольких одноименных переменных, которые я нажимаю " camel casing" (как это называлось на предыдущей работе). Прямо сейчас я на работе, которая имеет много тысяч строк полностью незафиксированного классического кода ASP с VBScript, и это кошмар, пытающийся понять вещи.
добавление загадочных символов в начале каждого имени переменной не требуется и показывает, что имя переменной само по себе недостаточно описательно. Большинство языков требуют тип переменной при объявлении в любом случае, так что информация уже доступна.
существует также ситуация, когда во время обслуживания необходимо изменить тип переменной. Пример: если переменная, объявленная как "uint_16 u16foo", должна стать 64-разрядной без знака, одна из двух вещей будет бывает:
- вы пройдете и измените имя каждой переменной (убедившись, что не шлангом каких-либо несвязанных переменных с тем же именем), или
- просто измените тип и не измените имя, что только вызовет путаницу.
Джоэл Спольски написал хороший пост в блоге об этом. http://www.joelonsoftware.com/articles/Wrong.html В основном это сводится к тому, чтобы не затруднять чтение кода, когда приличная IDE скажет вам, что вы хотите ввести переменную, если вы не можете вспомнить. Кроме того, если вы сделаете свой код достаточно раздельным, вам не нужно будет помнить, что переменная была объявлена как три страницы вверх.
не является областью более важной, чем тип в эти дни, например
* l for local
* a for argument
* m for member
* g for global
* etc
С современными методами рефакторинга старого кода, поиска и замены символа, потому что вы изменили его тип, утомительно, компилятор будет ловить изменения типа, но часто не будет ловить неправильное использование области, разумные соглашения об именах помогают здесь.
нет причин, почему бы вам не сделать правильно использование венгерской нотации. Это непопулярность из-за долгого бега назад-плеть против неправильно использовать венгерской нотации, особенно в Windows APIs.
в старые добрые времена, прежде чем что-либо похожее на IDE существовало для DOS (скорее всего, у вас не было достаточно свободной памяти для запуска компилятора под Windows, поэтому ваша разработка была выполнена в DOS), вы не получили никакой помощи от зависания вашего мыши на имя переменной. (Если вы имели мышкой.) С чем вам приходилось иметь дело, были функции обратного вызова событий, в которых все передавалось вам как 16-битный int (WORD) или 32-битный int (LONG WORD). Затем вы должны были привести этот параметр к соответствующим типам для данного типа события. По сути, большая часть API была практически без типов.
результат, API с такими именами параметров:
LRESULT CALLBACK WindowProc(HWND hwnd,
UINT uMsg,
WPARAM wParam,
LPARAM lParam);
обратите внимание, что имена wParam и lParam, хотя довольно ужасно, на самом деле не хуже, чем назвав их param1 и param2.
что еще хуже, окно 3.0 / 3.1 имело два типа указателей, ближний и Дальний. Так, например, возвращаемое значение из функции управления памятью LocalLock было PVOID, но возвращаемое значение из GlobalLock было LPVOID (с " L " долго). Это ужасное обозначение затем было расширено так, что a lОнг pстрока ointer была с префиксом lp, чтобы отличить это из строки, которая была просто Танос бы.
неудивительно, что была реакция против такого рода вещей.
венгерская нотация может быть полезна в языках без проверки типа времени компиляции, так как это позволит разработчику быстро напомнить себе о том, как используется конкретная переменная. Он ничего не делает для производительности или поведения. Он должен улучшить читаемость кода и в основном является вопросом вкуса и стиля кодирования. Именно по этой причине его критикуют многие разработчики - не у всех одинаковая проводка в мозгу.
для языков проверки типов во время компиляции это в основном бесполезно-прокрутка нескольких строк должна выявить декларацию и, таким образом, ввести. Если глобальные переменные или блок кода охватывают более одного экрана, возникают серьезные проблемы с дизайном и возможностью повторного использования. Таким образом, одна из критических замечаний заключается в том, что венгерская нотация позволяет разработчикам иметь плохой дизайн и легко сходить с рук. Вероятно, это одна из причин ненависти.
с другой стороны, могут быть случаи, когда даже языки проверки типов во время компиляции выгода от венгерской нотации -- пустота указатели дескрипторв win32 API. Это запутывает фактический тип данных, и там может быть полезно использовать венгерскую нотацию. Тем не менее, если можно узнать тип данных во время сборки, почему бы не использовать соответствующий тип данных.
В общем, нет никаких серьезных причин не использовать венгерскую нотацию. Это вопрос симпатий, политики и стиля кодирования.
как программист Python, венгерская нотация разваливается довольно быстро. В Python мне все равно, если что-то is строка-мне все равно, если это может действовать как строка (т. е. если она имеет ___str___() метод, который возвращает строку).
например, предположим, что у нас есть foo как целое число, 12
foo = 12
венгерская нотация говорит нам, что мы должны назвать это iFoo или что-то, чтобы обозначить это целое число, так что позже мы знаем, что это такое. За исключением Python, это не работает, или, скорее, это не имеет смысла. В Python я решаю, какой тип я хочу, когда я его использую. Мне нужна веревочка? хорошо, если я сделаю что-то вроде этого:
print "The current value of foo is %s" % foo
Примечание %s - строка. Фу - это не струна, а % оператор колл foo.___str___() и использовать полученный результат (если он существует). foo по-прежнему целое число, но мы рассматриваем его как строку, если нам нужна строка. Если мы хотим поплавок, то мы относимся к нему как к поплавку. В динамически типизированных языках как и Python, венгерская нотация бессмысленна, потому что не имеет значения, какой тип что-то, пока вы не используете его, и если вам нужен определенный тип, то просто убедитесь, что он приведен к этому типу (например,float(foo)) когда вы используете его.
обратите внимание, что динамические языки, такие как PHP, не имеют этого преимущества - PHP пытается сделать "правильную вещь" в фоновом режиме на основе неясного набора правил, которые почти никто не запомнил, что часто приводит к катастрофическим беспорядкам неожиданно. В этом деле, какой-то механизм именования, например $files_count или $file_name, может пригодиться.
на мой взгляд, венгерская нотация похожа на пиявок. Может быть, в прошлом они были полезны, или, по крайней мере, казались полезными, но в настоящее время это просто много дополнительной печати для не большой пользы.
IDE должна передавать эту полезную информацию. Венгерский мог бы иметь какой-то смысл (не много, но какой-то), когда IDE были намного менее продвинутыми.
приложения-венгерский-греческий для меня-в хорошем смысле
как инженер, а не программист, я сразу же взялся за статью Джоэла о достоинствах венгерских приложений: "Неправильный Код Выглядит Неправильно". Мне нравятся приложения венгерский, потому что это имитирует, как инженерия, наука и математика представляют уравнения и формулы с использованием суб - и супер-скриптовых символов (как и греческие буквы, математические операторы и т. д.). Возьмем конкретный пример закон Ньютона Универсальная Гравитация: сначала в стандартной математической нотации, а затем в приложениях венгерский псевдокод:
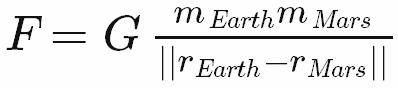
frcGravityEarthMars = G * massEarth * massMars / norm(posEarth - posMars)
в математической нотации наиболее заметными символами являются символы, представляющие вид информации, хранящейся в переменной: сила, масса, вектор положения и т. д. Индексы играют вторую скрипку, чтобы уточнить: позиция чего? Это именно то, что приложения венгерский делает; это говорит вам вид из того, что хранится в переменной сначала, а затем попадает в спецификацию-о самом близком коде можно получить математическую нотацию.
явно сильная типизация может разрешить безопасный и небезопасный пример строки из эссе Джоэла, но вы не определили бы отдельные типы для векторов положения и скорости; оба являются двойными массивами третьего размера, и все, что вы, вероятно, сделаете с одним, может применяться к другому. Кроме того, имеет смысл объединить положение и скорость (чтобы сделать State vector) или взять их точечный продукт, но, вероятно, не добавлять их. Как типизация позволяет первые два и запрещает второй, и как такая система распространяется на все возможные операции, которые вы можете защитить? Если только вы не были готовы кодировать всю математику и физику в вашей системе ввода.
кроме того, многие инженерные работы выполняются на слабо типизированных языках высокого уровня, таких как Matlab, или старых, таких как Fortran 77 или Ada.
Так что если у вас есть фантазии язык и IDE и приложения венгерский не поможет вам забыть об этом-многие люди, по-видимому, есть. Но для меня, худшего, чем начинающий программист, который работает на слабо или динамически типизированных языках, я могу писать лучший код быстрее с венгерскими приложениями, чем без них.
Это невероятно избыточно и бесполезно большинство современных IDEs, где они делают хорошую работу, чтобы сделать тип очевидным.
плюс -- для меня -- это просто раздражает видеть intI, strUserName и т. д. :)
Если я чувствую, что полезная информация передается, почему бы мне не поместить ее прямо там, где она доступна?
Im мой опыт, это плохо, потому что:
1 - тогда вы нарушаете весь код, если вам нужно изменить тип переменной (т. е. если вам нужно расширить 32-битное целое число до 64-битного целого числа);
2-это бесполезная информация, поскольку тип либо уже находится в объявлении, либо вы используете динамический язык, где фактический тип не должен быть таким важным в первую очередь.
кроме того, с языком, принимающим общее Программирование (т. е. функции где тип некоторых переменных не определяет, когда вы пишете функцию) или с динамической системой ввода (т. е. когда тип даже не определяется во время компиляции), как бы вы назвали свои переменные? И большинство современных языков поддерживают тот или иной, даже если в ограниченной форме.
на Джоэл Спольски делает неправильный код выглядеть неправильно Он объясняет, что то, что все думают о венгерской нотации (которую он называет венгерскими системами), не то, что было на самом деле предназначено (то, что он называет венгерскими приложениями). Прокрутите вниз до Я Венгрия заголовок, чтобы увидеть эту дискуссию.
в принципе, венгерские системы бесполезны. Он просто говорит вам то же самое, что скажет вам ваш компилятор и/или IDE.
Приложения Венгрии говорит вам, что переменная должна означать, и на самом деле может быть полезна.
Я всегда думал, что префикс или два в нужном месте не повредит. Я думаю, что если я могу передать что-то полезное, например: "Эй, это интерфейс, не рассчитывайте на конкретное поведение" прямо там, как в IEnumerable, я должен это сделать. Комментарий может загромождать вещи гораздо больше, чем просто один или два символа.
Это полезное Соглашение для именования элементов управления в форме (btnOK,txtLastName и т. д.), если список элементов управления отображается в алфавитном раскрывающемся списке в IDE.
Я склонен использовать венгерскую нотацию с ASP.NET серверные элементы управления только, в противном случае мне слишком сложно понять, какие элементы управления находятся в форме.
возьмите этот фрагмент кода:
<asp:Label ID="lblFirstName" runat="server" Text="First Name" />
<asp:TextBox ID="txtFirstName" runat="server" />
<asp:RequiredFieldValidator ID="rfvFirstName" runat="server" ... />
Если кто-то может показать лучший способ иметь этот набор имен управления без венгерского, я бы соблазнился перейти к нему.
статья Джоэла великолепна, но, похоже, она опускает один важный момент:
венгерский делает определенную "идею" (вид + имя идентификатора) уникальной, или почти уникальная, по всей кодовой базе-даже очень большая кодовая база.
Это огромный для обслуживания кода. Это означает, что вы можете использовать хороший однострочный текстовый поиск (grep, findstr, "найти во всех файлах"), чтобы найти каждое упоминание об этой "идее".
Почему это важно, когда у нас есть IDE, которые знают, как читать код? Потому что у них пока не очень хорошо получается. Это трудно увидеть в небольшой кодовой базе, но очевидно в большом - когда "идея" может быть упомянута в комментариях, XML файлы, Perl скрипты, а также в местах вне системы управления версиями (документы, Вики, базы данных ошибок).
вам нужно быть немного осторожным даже здесь-например, вставка токенов в макросы C / C++ может скрывать упоминания идентификатора. Такие случаи можно рассматривать с использованием соглашения о кодировании, и в любом случае они, как правило, влияют только на меньшинство идентификаторов в кодовая база.
P. S. Кстати об использовании системы типов и венгерско - лучше использовать оба. Вам нужен только неправильный код, чтобы выглядеть неправильно, если компилятор не поймает его для вас. Есть много случаев, когда невозможно заставить компилятор поймать его. Но где это возможно - да, пожалуйста, сделайте это вместо этого!
при рассмотрении осуществимости, однако, учитывайте негативные последствия разделения типов. например, в C# накрутка "int" с не встроенным типом имеет огромные последствия. Поэтому есть смысл в некоторых ситуациях, но не во всех из них.
развенчание преимуществ венгерской нотации
- Он обеспечивает способ различения переменных.
если тип-это все, что отличает одно значение от другого, то это может быть только для преобразования одного типа в другой. Если у вас есть то же значение, что преобразования между типами, скорее всего, вы должны делать это в функцию для преобразования. (Я видел hungarianed VB6 остатки использования строки для всех своих параметров метода просто потому, что они не могли понять, как десериализовать объект JSON или правильно понять, как объявить или использовать типы nullable.) если у вас есть две переменные, отличающиеся только венгерским префиксом, и они не являются преобразованием из одного в другой, то вам нужно уточнить свое намерение с ними.
- это делает код более читаемым.
я нашел, что венгерский нотация делает людей ленивыми с их переменными именами. У них есть что-то, чтобы отличить его, и они не чувствуют необходимости уточнять его цель. Это то, что вы обычно найти в венгерской комбинации кода и современные: sSQL и groupSelectSql (или обычно нет sSQL вообще, потому что они должны использовать ORM, который был введен более ранними разработчиками.), sValue против formCollectionValue (или обычно нет sValue, потому что они случайно находятся в MVC и должны быть использование функций привязки модели), sType против publishSource и т. д.
это не может быть читаемость. Я вижу больше sTemp1, sTemp2... sTempN из любой hungarianed в VB6 остаток, чем все остальные вместе взятые.
- это предотвращает ошибки.
это было бы в силу числа 2, которое является ложным.
по словам мастера:
http://www.joelonsoftware.com/articles/Wrong.html
интересное чтение, как обычно.
экстракты:
нескольким причинам:
- любая современная IDE даст вам тип переменной, просто наведя курсор мыши на переменную.
- большинство имен типов являются длинными (подумайте HttpClientRequestProvider) для разумного использования в качестве префикса.
- информация о типе не содержит право информация, это просто перефразирование объявления переменной, а не изложение цель переменной (думаю тип myinteger и pageSize).
Я не думаю, что все яростно против него. В языках без статических типов это довольно полезно. Я определенно предпочитаю, когда он используется для предоставления информации, которая еще не входит в тип. Как в C,тип char * szname метода говорит, что переменная будет ссылаться на строку с нулевым завершением - это не подразумевается в char* - конечно, typedef также поможет.
у Джоэла была отличная статья об использовании венгерского, чтобы сказать, была ли переменная закодирована HTML или не:
http://www.joelonsoftware.com/articles/Wrong.html
в любом случае, я не люблю венгерский, когда он используется для передачи информации, которую я уже знаю.
конечно, когда 99% программистов соглашаются на что-то, что-то не так. Причина, по которой они согласны здесь, заключается в том, что большинство из них никогда не использовали венгерскую нотацию правильно.
для подробного аргумента я отсылаю вас к сообщению в блоге, которое я сделал по этому вопросу.
http://codingthriller.blogspot.com/2007/11/rediscovering-hungarian-notation.html
Я начал кодировать примерно в то время, когда была изобретена венгерская нотация, и в первый раз я был вынужден использовать ее в проекте, который я ненавидел.
через некоторое время я понял, что когда это было сделано правильно, это действительно помогло, и в эти дни я люблю его.
но, как и все хорошее, это должно быть изучено и понято, и для того, чтобы сделать это правильно, требуется время.
венгерская нотация была злоупотреблена, особенно Microsoft, что привело к префиксам длиннее имени переменной и показывает, что она довольно жесткая, особенно при изменении типов (печально известный lparam/wparam, разного типа/размера в Win16, идентичный в Win32).
таким образом, как из-за этого злоупотребления, так и его использования M$, он был записан как бесполезный.
на моей работе мы кодируем на Java, но основатель cames из MFC world, поэтому используйте аналогичный стиль кода (выровненные фигурные скобки, I вот так!, заглавные для имен методов, я привык к этому, префикс, такой как m_ для членов класса (полей), s_ для статических членов и т. д.).
и они сказали, что все переменные должны иметь префикс, показывающий его тип (например. BufferedReader называется brData). Что показано как плохая идея, поскольку типы могут меняться, но имена не следуют, или кодеры не согласуются в использовании этих префиксов (я даже вижу aBuffer, theProxy и т. д.!).
лично я выбрал для нескольких префиксов, которые я найти полезным, наиболее важным является B для префикса булевых переменных, так как они являются единственными, где я разрешаю синтаксис, как if (bVar) (не использовать автоадресацию некоторых значений на true или false).
Когда я кодировал в C, я использовал префикс для переменных, выделенных с malloc, в качестве напоминания он должен быть освобожден позже. Так далее.
Итак, в основном, я не отвергаю эту нотацию в целом, но взял то, что кажется подходящим для моих нужд.
И, конечно, внося свой вклад в какой-то проект (работа, открытый исходный код), я просто используйте конвенции на месте!