профили gprof против cachegrind
пытаясь оптимизировать код, я немного озадачен различиями в профилях, созданных kcachegrdind и gprof. В частности, если я использую gprof (компиляция с -pg переключатель и т. д.), У меня есть это:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
89.62 3.71 3.71 204626 0.02 0.02 objR<true>::R_impl(std::vector<coords_t, std::allocator<coords_t> > const&, std::vector<unsigned long, std::allocator<unsigned long> > const&) const
5.56 3.94 0.23 18018180 0.00 0.00 W2(coords_t const&, coords_t const&)
3.87 4.10 0.16 200202 0.00 0.00 build_matrix(std::vector<coords_t, std::allocator<coords_t> > const&)
0.24 4.11 0.01 400406 0.00 0.00 std::vector<double, std::allocator<double> >::vector(std::vector<double, std::allocator<double> > const&)
0.24 4.12 0.01 100000 0.00 0.00 Wrat(std::vector<coords_t, std::allocator<coords_t> > const&, std::vector<coords_t, std::allocator<coords_t> > const&)
0.24 4.13 0.01 9 1.11 1.11 std::vector<short, std::allocator<short> >* std::__uninitialized_copy_a<__gnu_cxx::__normal_iterator<std::vector<short, std::alloca
что, кажется, предполагает, что мне не нужно беспокоиться, глядя куда угодно, кроме ::R_impl(...)
в то же время, если я компилирую без -pg переключатель и бегите valgrind --tool=callgrind ./a.out вместо этого у меня есть что-то другое: Вот скриншот kcachegrind вывод
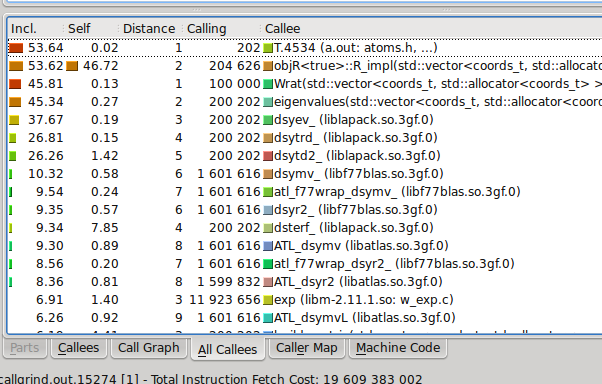
если я правильно интерпретирую это, кажется, предполагает, что ::R_impl(...) занимает около 50% времени, в то время как другая половина уходит в линейной алгебре (Wrat(...), eigenvalues и основные вызовы lapack), который был ниже в gprof профиль.
я понимаю, что gprof и cachegrind используйте разные методы, и я бы не беспокоился, если бы их результаты были несколько разными. Но здесь все выглядит совсем по-другому. как интерпретировать их. Есть идеи или предложения?
2 ответов
вы смотрите не на ту колонку. Вы должны посмотреть на второй столбец в выходных данных kcachegrind, тот, который называется "self". Это время, затрачиваемое конкретной подпрограммой только без учета ее детей. Первый столбец имеет кумулятивное время (оно равно 100% машинного времени для основного), и это не так информативно (на мой взгляд).
обратите внимание, что из вывода kcachegrind вы можете видеть, что общее время процесса составляет 53,64 секунды, а время потрачено в подпрограмме" R_impl " 46.72 секунды, что составляет 87% от общего времени. Так что gprof и kcachegrind согласны почти идеально.
gprof Это instrumented профайлер, callgrind это забора профайлер. С помощью инструментального профилировщика вы получаете накладные расходы для каждого входа и выхода функции, которые могут исказить профиль, особенно если у вас есть относительно небольшие функции, которые вызываются много раз. Профилировщики выборки, как правило, более точны - они немного замедляют общее выполнение программы, но это, как правило, оказывает одинаковое относительное влияние на все функции.
попробуйте бесплатно 30 день оценки увеличение от RotateRight - я подозреваю, что это даст вам профиль, который согласуется больше с callgrind чем с gprof.