Расстояние Левенштейна:как лучше обрабатывать Слова, меняющие позиции?
у меня был некоторый успех в сравнении строк с помощью PHP Левенштейна
9 ответов
N-граммы
использовать N-граммы, которые поддерживают многосимвольные транспозиции по всему тексту.
общая идея заключается в том, что вы разделяете две рассматриваемые строки на все возможные 2-3 символьные подстроки (n-граммы) и рассматриваете количество общих n-граммов между двумя строками как метрику их сходства. Затем это можно нормализовать, разделив общее число на общее количество n-граммов в более длинной строке. Это тривиально для расчета, но довольно мощно.
для примера предложений:
A. The quick brown fox
B. brown quick The fox
C. The quiet swine flu
A и B поделиться 18 2-г
A и C доля только 8 2-г
из 20 всего возможного.
Это было обсуждено более подробно в Gravano et al. бумага!--5-->.
tf-idf и косинусное сходство
не так тривиально альтернативным, но основанным на теории информации было бы использование термина частота термина-обратная частота документа (TF-idf) чтобы взвесить маркеры, построить векторы предложений, а затем использовать Косинус сходство как метрика сходства.
алгоритм:
- вычислить 2-символьные частоты токенов (tf) на предложение.
- вычислить частоты обратного предложения (idf), которая является логарифмом частного числа из всех предложений в корпусе (в данном случае 3), разделенных на количество раз, конкретный знак появляется во всех предложениях. В этом случае th во всех предложениях, поэтому он имеет нулевое информационное содержание (log (3/3)=0).
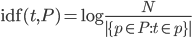
- создайте матрицу TF-idf путем умножения соответствующих ячеек в таблицах tf и idf.
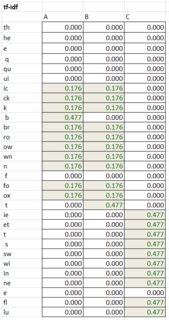
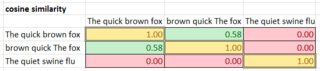
- наконец, вычислите матрицу косинусного сходства для всех пар предложений, где A и B-веса из таблицы TF-idf для соответствующие токены. Диапазон от 0 (не похож) до 1 (равно).
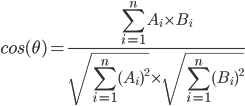
модификации Левенштейна и метафон
что касается других ответов. Дамерау–Левенштейна modificication поддерживает только транспозиции два соседних символы. метафон был разработан, чтобы соответствовать словам, которые звучат одинаково и не для сопоставления сходства.
его легко. Просто используйте Дамерау-Левенштейна расстояние по словам вместо букв.
вы также можете попробовать это. (просто дополнительное предложение)
$one = metaphone("The quick brown fox"); // 0KKBRNFKS
$two = metaphone("brown quick The fox"); // BRNKK0FKS
$three = metaphone("The quiet swine flu"); // 0KTSWNFL
similar_text($one, $two, $percent1); // 66.666666666667
similar_text($one, $three, $percent2); // 47.058823529412
similar_text($two, $three, $percent3); // 23.529411764706
Это покажет, что 1 и 2 более похожи, чем один и три и два и три.
я внедрял Левенштейна в проверку орфографии.
то, что вы просите, - это подсчет транспозиций как 1 edit.
это легко, если вы хотите только подсчитать транспозиции одного слова. Однако для транспозиции слов 2 или более, добавление к алгоритму является худшим сценарием !(max(wordorder1.length(), wordorder2.length())). Добавление нелинейного подалгоризма к уже квадратичному алгоритму не является хорошей идеей.
вот как это было работа.
if (wordorder1[n] == wordorder2[n-1])
{
min(workarray[x-1, y] + 1, workarray[x, y-1] + 1, workarray[x-2, y-2]);
}
else
{
min(workarray[x-1, y] + 1, workarray[x, y-1] + 1);
}
только для прикосновения транспозиций. Если вы хотите все транспозиции, вам придется для каждой позиции работать назад от этой точки сравнения
1[n] == 2[n-2].... 1[n] == 2[0]....
Итак, вы видите, почему они не включают в стандартный способ.
Take ответ и внесите следующее изменение:
void match(trie t, char* w, string s, int budget){
if (budget < 0) return;
if (*w=='') print s;
foreach (char c, subtrie t1 in t){
/* try matching or replacing c */
match(t1, w+1, s+c, (*w==c ? budget : budget-1));
/* try deleting c */
match(t1, w, s, budget-1);
}
/* try inserting *w */
match(t, w+1, s + *w, budget-1);
/* TRY SWAPPING FIRST TWO CHARACTERS */
if (w[1]){
swap(w[0], w[1]);
match(t, w, s, budget-1);
swap(w[0], w[1]);
}
}
Это для поиска словаря в trie, но для сопоставления с одним словом это та же идея. Вы делаете ветвь и привязку, и в любой момент Вы можете сделать любое изменение, которое вам нравится, если вы дадите ему цену.
Я считаю, что это яркий пример использования вектор-космическая поисковая система.
в этом методе каждый документ по существу становится вектором с таким количеством измерений, как есть разные слова во всем корпусе; аналогичные документы затем занимают соседние области в этом векторном пространстве. одним из приятных свойств этой модели является то, что запросы также являются просто документами: чтобы ответить на запрос, вы просто вычисляете их положение в векторном пространстве, и ваши результаты ближайшие документы вы можете найти. я уверен, что есть решения get-and-go для PHP.
чтобы размыть результаты из векторного пространства, вы можете рассмотреть возможность использования метода обработки естественного языка и использовать levenshtein для создания вторичных запросов для похожих слов, которые встречаются в вашем общем словаре.
Если первая строка-A, а вторая-B:
- разделить A и B на слова
- для каждого слова в A найдите лучшее подходящее слово в B (используя levenshtein)
- удалите это слово из B и поместите его в B* с тем же индексом, что и соответствующее слово в A.
- теперь сравните A и B*
пример:
A: The quick brown fox
B: Quick blue fox the
B*: the Quick blue fox
вы можете улучшить Шаг 2, сделав это за несколько проходов, сначала находя только точные совпадения, затем найти близкие совпадения для слов в A, которые еще не имеют компаньона в B*, затем менее близкие совпадения и т. д.