Regex соответствуют только целым словам
у меня есть выражение regex, которое я использую, чтобы найти все слова в данном блоке контента, нечувствительные к регистру, которые содержатся в глоссарии, хранящемся в базе данных. Вот мой шаблон:
/($word)/i
проблема в том, если я использую /(Foo)/i после слова Food подбирается. По обе стороны слова должны быть пробелы или граница слова.
как я могу изменить свое выражение, чтобы соответствовать только слову Foo когда это слово в начале, середине или конец предложения?
4 ответов
используйте границы слов:
/\b($word)\b/i
или если вы ищете "С. П. Е. К. Т. Р. Е.", Как в Примере Синан Ünür это:
/(?:\W|^)(\Q$word\E)(?:\W|$)/i
чтобы соответствовать любому целому слову, вы бы использовали шаблон (\w+)
предполагая, что вы используете PCRE или что-то подобное:
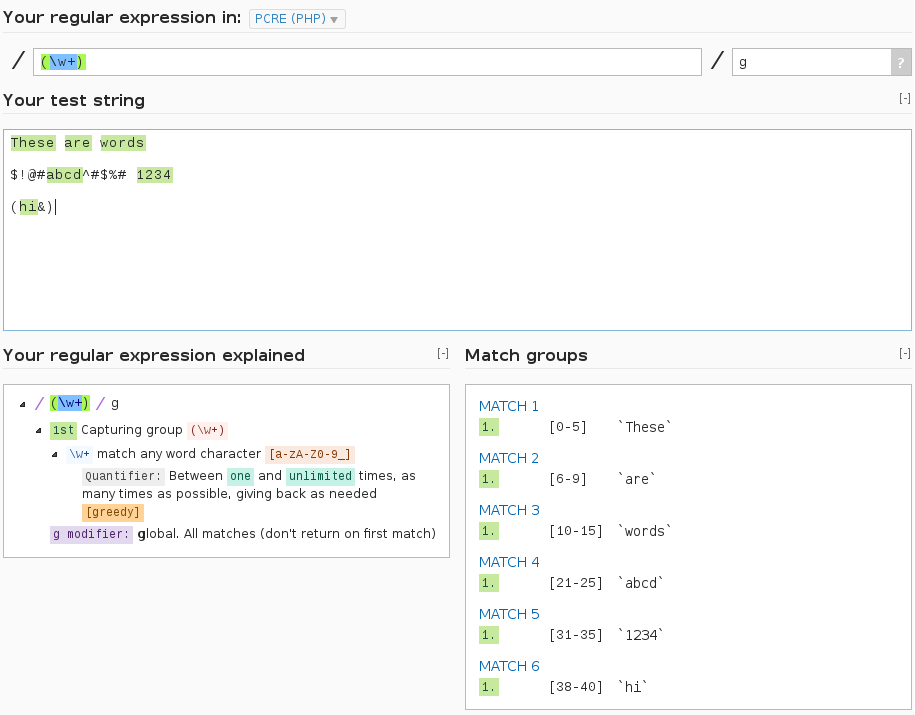
выше Скриншот взят из этого живой пример: http://regex101.com/r/cU5lC2
сопоставление любого целого слова в командной строке с (\w+)
я буду использовать интерактивная оболочка phpsh on Ubuntu 12.10 для демонстрации PCRE regex engine С помощью метода, известного как функции preg_match
запустите phpsh, поместите некоторое содержимое в переменную, сопоставьте слово.
el@apollo:~/foo$ phpsh
php> $content1 = 'badger'
php> $content2 = '1234'
php> $content3 = '$%^&'
php> echo preg_match('(\w+)', $content1);
1
php> echo preg_match('(\w+)', $content2);
1
php> echo preg_match('(\w+)', $content3);
0
метод preg_match использовал движок PCRE в языке PHP для анализа переменных:$content1, $content2 и $content3 С (\w)+ узор.
$content1 и $content2 содержат по крайней мере одно слово, $content3-нет.
сопоставьте количество буквальных слов на командная строка с (dart|fart)
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(dart|fart)', $gun1);
1
php> echo preg_match('(dart|fart)', $gun2);
1
php> echo preg_match('(dart|fart)', $gun3);
1
php> echo preg_match('(dart|fart)', $gun4);
0
переменные gun1 и gun2 содержат строку dart или fart. gun4 не. Однако это может быть проблема, которая ищет word fart игр farty. Чтобы исправить это, примените границы слов в regex.
матч буквальные слова в командной строке с границами слов.
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(\bdart\b|\bfart\b)', $gun1);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun2);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun3);
0
php> echo preg_match('(\bdart\b|\bfart\b)', $gun4);
0
таким образом, это то же самое, что и предыдущий пример, за исключением слова fart С \b граница слова не существует в содержание: farty.
используя \b может дать удивительные результаты. Вам было бы лучше выяснить, что отделяет слово от его определения, и включить эту информацию в свой шаблон.
#!/usr/bin/perl
use strict; use warnings;
use re 'debug';
my $str = 'S.P.E.C.T.R.E. (Special Executive for Counter-intelligence,
Terrorism, Revenge and Extortion) is a fictional global terrorist
organisation';
my $word = 'S.P.E.C.T.R.E.';
if ( $str =~ /\b(\Q$word\E)\b/ ) {
print , "\n";
}
выход:
Compiling REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b"
Final program:
1: BOUND (2)
2: OPEN1 (4)
4: EXACT (9)
9: CLOSE1 (11)
11: BOUND (12)
12: END (0)
anchored "S.P.E.C.T.R.E." at 0 (checking anchored) stclass BOUND minlen 14
Guessing start of match in sv for REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b" against "S.P
.E.C.T.R.E. (Special Executive for Counter-intelligence,"...
Found anchored substr "S.P.E.C.T.R.E." at offset 0...
start_shift: 0 check_at: 0 s: 0 endpos: 1
Does not contradict STCLASS...
Guessed: match at offset 0
Matching REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b" against "S.P.E.C.T.R.E. (Special Exec
utive for Counter-intelligence,"...
0 | 1:BOUND(2)
0 | 2:OPEN1(4)
0 | 4:EXACT (9)
14 | 9:CLOSE1(11)
14 | 11:BOUND(12)
failed...
Match failed
Freeing REx: "\b(S\.P\.E\.C\.T\.R\.E\.)\b"
используйте границы слов \b,
в моей среде работает следующее (используя четыре эскейпа): Mac, safari версии 10.0.3 (12602.4.8)
var myReg = new RegExp(‘\\b’+ variable + ‘\\b’, ‘g’)