Scrapy - как управлять файлами cookie / сеансами
Я немного смущен тем, как cookies работают с Scrapy, и как вы управляете этими cookies.
это по сути упрощенная версия того, что я пытаюсь сделать:
как работает сайт:
при посещении веб-сайта вы получаете cookie сеанса.
когда вы делаете поиск, веб-сайт помнит, что вы искали, поэтому, когда вы делаете что-то вроде перехода на следующую страницу результатов, он знает, что это поиск дело.
мой скрипт:
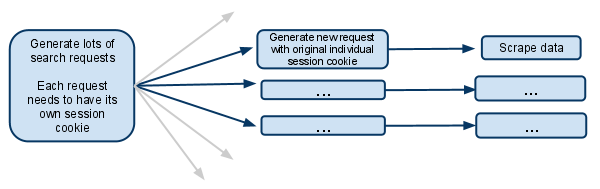
мой паук имеет начальный url searchpage_url
в searchpage по просьбе parse() и ответ поисковой формы передается в search_generator()
search_generator() затем yields много поисковых запросов с помощью FormRequest и ответ поисковой формы.
каждый из этих FormRequests и последующие дочерние запросы должны иметь свой собственный сеанс, поэтому он должен иметь свой собственный cookiejar, и это собственный файл cookie сеанса.
Я видел раздел документов, в котором говорится о мета-опции, которая останавливает объединение файлов cookie. Что это значит? Означает ли это, что паук, который делает запрос, будет иметь свой собственный cookiejar на всю оставшуюся жизнь?
если куки-файлы находятся на уровне паука, то как это работает, когда несколько пауков порождены? Можно ли сделать только первый запрос генератора порождать новых пауков и убедиться, что с тех пор только что spider занимается будущими запросами?
Я предполагаю, что мне нужно отключить несколько параллельных запросов.. в противном случае один паук будет выполнять несколько поисков в одном файле cookie сеанса, а будущие запросы будут относиться только к самому последнему поиску?
Я смущен, любое разъяснение будет очень получено!
EDIT:
другого варианта я просто думал полностью управлять cookie сеанса вручную, и передавая его от одного запроса к другому.
Я полагаю, что это означало бы отключение cookies.. а затем захватывает cookie сеанса из ответа поиска и передает его вместе с каждым последующим запросом.
это то, что вы должны сделать в этой ситуации?
4 ответов
три года спустя, я думаю, это именно то, что вы искали: http://doc.scrapy.org/en/latest/topics/downloader-middleware.html#std:reqmeta-cookiejar
просто используйте что-то вроде этого в методе start_requests вашего паука:
for i, url in enumerate(urls):
yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},
callback=self.parse_page)
и помните, что для последующих запросов вам нужно явно повторно подключить cookiejar каждый раз:
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
from scrapy.http.cookies import CookieJar
...
class Spider(BaseSpider):
def parse(self, response):
'''Parse category page, extract subcategories links.'''
hxs = HtmlXPathSelector(response)
subcategories = hxs.select(".../@href")
for subcategorySearchLink in subcategories:
subcategorySearchLink = urlparse.urljoin(response.url, subcategorySearchLink)
self.log('Found subcategory link: ' + subcategorySearchLink), log.DEBUG)
yield Request(subcategorySearchLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True})
'''Use dont_merge_cookies to force site generate new PHPSESSID cookie.
This is needed because the site uses sessions to remember the search parameters.'''
def extractItemLinks(self, response):
'''Extract item links from subcategory page and go to next page.'''
hxs = HtmlXPathSelector(response)
for itemLink in hxs.select(".../a/@href"):
itemLink = urlparse.urljoin(response.url, itemLink)
print 'Requesting item page %s' % itemLink
yield Request(...)
nextPageLink = self.getFirst(".../@href", hxs)
if nextPageLink:
nextPageLink = urlparse.urljoin(response.url, nextPageLink)
self.log('\nGoing to next search page: ' + nextPageLink + '\n', log.DEBUG)
cookieJar = response.meta.setdefault('cookie_jar', CookieJar())
cookieJar.extract_cookies(response, response.request)
request = Request(nextPageLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True, 'cookie_jar': cookieJar})
cookieJar.add_cookie_header(request) # apply Set-Cookie ourselves
yield request
else:
self.log('Whole subcategory scraped.', log.DEBUG)
Я думаю, что самым простым подходом было бы запустить несколько экземпляров одного и того же spider, используя поисковый запрос в качестве аргумента spider (который будет получен в конструкторе), чтобы повторно использовать функцию управления cookies Scrapy. Таким образом, у вас будет несколько экземпляров spider, каждый из которых будет сканировать один конкретный поисковый запрос и его результаты. Но вам нужно запустить пауков самостоятельно с:
scrapy crawl myspider -a search_query=something
или вы можете использовать Scrapyd для запуска всех пауков через JSON ПРИКЛАДНОЙ ПРОГРАММНЫЙ ИНТЕРФЕЙС.
def parse(self, response):
# do something
yield scrapy.Request(
url= "http://new-page-to-parse.com/page/4/",
cookies= {
'h0':'blah',
'taeyeon':'pretty'
},
callback= self.parse
)