среде MATLAB/Октава - обобщенное матричное умножение
Я хотел бы сделать функцию для обобщения умножения матрицы. В принципе, он должен умножать стандартную матрицу, но он должен позволять изменять два двоичных оператора product / sum любой другой функцией.
цель состоит в том, чтобы быть максимально эффективным, как с точки зрения процессора и памяти. Конечно, он всегда будет менее эффективным, чем A*B, но гибкость Операторов здесь.
вот несколько команд, которые я мог придумать после прочтения различные интересные темы:
A = randi(10, 2, 3);
B = randi(10, 3, 4);
% 1st method
C = sum(bsxfun(@mtimes, permute(A,[1 3 2]),permute(B,[3 2 1])), 3)
% Alternative: C = bsxfun(@(a,b) mtimes(a',b), A', permute(B, [1 3 2]))
% 2nd method
C = sum(bsxfun(@(a,b) a*b, permute(A,[1 3 2]),permute(B,[3 2 1])), 3)
% 3rd method (Octave-only)
C = sum(permute(A, [1 3 2]) .* permute(B, [3 2 1]), 3)
% 4th method (Octave-only): multiply nxm A with nx1xd B to create a nxmxd array
C = bsxfun(@(a, b) sum(times(a,b)), A', permute(B, [1 3 2]));
C = C2 = squeeze(C(1,:,:)); % sum and turn into mxd
проблема с методами 1-3 заключается в том, что они будут генерировать n матриц перед их свертыванием с помощью sum(). 4 лучше, потому что он делает sum () внутри bsxfun, но bsxfun все еще генерирует N матриц (за исключением того, что они в основном пусты, содержащие только вектор ненулевых значений, являющихся суммами, остальное заполняется 0, чтобы соответствовать измерениям требование.)
то, что я хотел бы, - это что-то вроде 4-го метода, но без бесполезного 0, чтобы сэкономить память.
есть идеи?
4 ответов
вот немного более полированная версия решения, которое вы опубликовали, с некоторыми небольшими улучшениями.
мы проверяем, есть ли у нас больше строк, чем столбцов или наоборот, а затем делаем умножение соответственно, выбирая либо умножать строки с матрицами, либо матрицы со столбцами (таким образом, делая наименьшее количество итераций цикла).
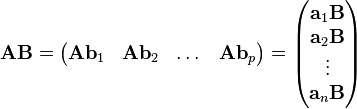
Примечание: это не всегда может быть лучшей стратегией (идет мимо строки вместо столбцов), даже если строк меньше, чем столбцов; тот факт, что массивы MATLAB хранятся в колонка-главный заказ в памяти делает его более эффективным для того чтобы отрезать столбцами, по мере того как элементы хранятся последовательно. В то время как доступ к строкам включает в себя обход элементов по успехов (что не является дружественным к кэшу -- think пространственная локальность).
кроме этого, код должен обрабатывать двойной/один/комплекс, полный / разреженный (и ошибки, где это не является возможной комбинацией). Он также уважает пустые матрицы и нулевые измерения.
function C = my_mtimes(A, B, outFcn, inFcn)
% default arguments
if nargin < 4, inFcn = @times; end
if nargin < 3, outFcn = @sum; end
% check valid input
assert(ismatrix(A) && ismatrix(B), 'Inputs must be 2D matrices.');
assert(isequal(size(A,2),size(B,1)),'Inner matrix dimensions must agree.');
assert(isa(inFcn,'function_handle') && isa(outFcn,'function_handle'), ...
'Expecting function handles.')
% preallocate output matrix
M = size(A,1);
N = size(B,2);
if issparse(A)
args = {'like',A};
elseif issparse(B)
args = {'like',B};
else
args = {superiorfloat(A,B)};
end
C = zeros(M,N, args{:});
% compute matrix multiplication
% http://en.wikipedia.org/wiki/Matrix_multiplication#Inner_product
if M < N
% concatenation of products of row vectors with matrices
% A*B = [a_1*B ; a_2*B ; ... ; a_m*B]
for m=1:M
%C(m,:) = A(m,:) * B;
%C(m,:) = sum(bsxfun(@times, A(m,:)', B), 1);
C(m,:) = outFcn(bsxfun(inFcn, A(m,:)', B), 1);
end
else
% concatenation of products of matrices with column vectors
% A*B = [A*b_1 , A*b_2 , ... , A*b_n]
for n=1:N
%C(:,n) = A * B(:,n);
%C(:,n) = sum(bsxfun(@times, A, B(:,n)'), 2);
C(:,n) = outFcn(bsxfun(inFcn, A, B(:,n)'), 2);
end
end
end
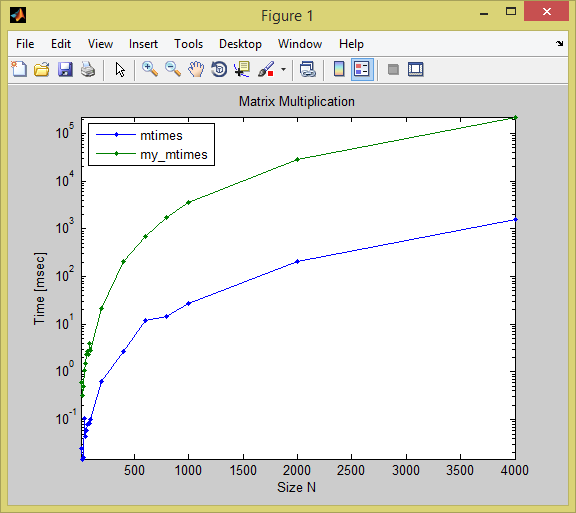
сравнение
функция, несомненно, медленнее во всем, но для больших размеров она на порядок хуже, чем встроенная матрица-умножение:
(tic/toc times in seconds)
(tested in R2014a on Windows 8)
size mtimes my_mtimes
____ __________ _________
400 0.0026398 0.20282
600 0.012039 0.68471
800 0.014571 1.6922
1000 0.026645 3.5107
2000 0.20204 28.76
4000 1.5578 221.51
вот тестовый код:
sz = [10:10:100 200:200:1000 2000 4000];
t = zeros(numel(sz),2);
for i=1:numel(sz)
n = sz(i); disp(n)
A = rand(n,n);
B = rand(n,n);
tic
C = A*B;
t(i,1) = toc;
tic
D = my_mtimes(A,B);
t(i,2) = toc;
assert(norm(C-D) < 1e-6)
clear A B C D
end
semilogy(sz, t*1000, '.-')
legend({'mtimes','my_mtimes'}, 'Interpreter','none', 'Location','NorthWest')
xlabel('Size N'), ylabel('Time [msec]'), title('Matrix Multiplication')
axis tight
дополнительно
для полноты картины ниже приведены еще два наивных способы реализации обобщенного умножения матрицы (если вы хотите сравнить производительность, замените последнюю часть my_mtimes функция с любым из этих). Я даже не буду утруждать себя публикацией их прошедшего времени:)
C = zeros(M,N, args{:});
for m=1:M
for n=1:N
%C(m,n) = A(m,:) * B(:,n);
%C(m,n) = sum(bsxfun(@times, A(m,:)', B(:,n)));
C(m,n) = outFcn(bsxfun(inFcn, A(m,:)', B(:,n)));
end
end
и другой способ (с тройным контуром):
C = zeros(M,N, args{:});
P = size(A,2); % = size(B,1);
for m=1:M
for n=1:N
for p=1:P
%C(m,n) = C(m,n) + A(m,p)*B(p,n);
%C(m,n) = plus(C(m,n), times(A(m,p),B(p,n)));
C(m,n) = outFcn([C(m,n) inFcn(A(m,p),B(p,n))]);
end
end
end
что попробовать дальше?
если вы хотите выжать больше производительности, вам придется перейти на C / C++ MEX-файл, чтобы сократить накладные расходы интерпретируемого Код MATLAB. Вы все еще можете воспользоваться оптимизированными процедурами BLAS/LAPACK, вызвав их из MEX-файлов (см. вторая часть этого поста для примера). MATLAB поставляется с Intel MKL библиотека, которую, честно говоря, вы не можете победить, когда дело доходит до вычислений линейной алгебры на процессорах Intel.
другие уже упоминали несколько представлений об обмене файлами, которые реализуют универсальные матричные процедуры как MEX-файлы (см. @natan'ы ответ). Они особенно эффективны, если вы связываете их с оптимизированной библиотекой BLAS.
почему бы просто не использовать bsxfunспособность принимать произвольную функцию?
C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1);
здесь
-
f- это внешняя функция (описанный в sum в случае умножения матрицы). Он должен принимать 3D-массив произвольного размераmxnxpи работать вдоль его столбцов, чтобы вернуть1xmxpмассив. -
g- это внутренний функция (соответствует продукт в случае умножения матрицы). Согласноbsxfun, он должен принимать в качестве входных данных либо два вектора столбцов одинакового размера, либо один вектор столбцов и один скаляр, и возвращать в качестве выходных данных вектор столбцов того же размера, что и входные данные.
это работает в Matlab. Я не проверял в Октаве.
Пример 1: Матрица-умножение:
>> f = @sum; %// outer function: sum
>> g = @times; %// inner function: product
>> A = [1 2 3; 4 5 6];
>> B = [10 11; -12 -13; 14 15];
>> C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1)
C =
28 30
64 69
проверка:
>> A*B
ans =
28 30
64 69
Пример 2: рассмотрим две вышеуказанные матрицы с
>> f = @(x,y) sum(abs(x)); %// outer function: sum of absolute values
>> g = @(x,y) max(x./y, y./x); %// inner function: "symmetric" ratio
>> C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1)
C =
14.8333 16.1538
5.2500 5.6346
проверка: вручную вычислить C(1,2):
>> sum(abs( max( (A(1,:))./(B(:,2)).', (B(:,2)).'./(A(1,:)) ) ))
ans =
16.1538
после изучения нескольких функций обработки, таких как bsxfun, кажется, что с их помощью невозможно будет сделать прямое умножение Матрицы (я имею в виду, что временные продукты не хранятся в памяти, а суммируются как можно скорее, а затем обрабатываются другие суммированные продукты), потому что они имеют выход фиксированного размера (либо такой же, как вход, либо с расширением bsxfun singleton декартовое произведение размеров двух входов). Однако можно немного обмануть Октаву (который не работает с MatLab, который проверяет выходные размеры):
C = bsxfun(@(a,b) sum(bsxfun(@times, a, B))', A', sparse(1, size(A,1)))
C = bsxfun(@(a,b) sum(bsxfun(@times, a, B))', A', zeros(1, size(A,1), 2))(:,:,2)
однако не используйте их, потому что выведенные значения не являются надежными (Октава может калечить или даже удалять их и возвращать 0!).
Итак, сейчас я просто реализую полу-векторизованную версию, вот моя функция:
function C = genmtimes(A, B, outop, inop)
% C = genmtimes(A, B, inop, outop)
% Generalized matrix multiplication between A and B. By default, standard sum-of-products matrix multiplication is operated, but you can change the two operators (inop being the element-wise product and outop the sum).
% Speed note: about 100-200x slower than A*A' and about 3x slower when A is sparse, so use this function only if you want to use a different set of inop/outop than the standard matrix multiplication.
if ~exist('inop', 'var')
inop = @times;
end
if ~exist('outop', 'var')
outop = @sum;
end
[n, m] = size(A);
[m2, o] = size(B);
if m2 ~= m
error('nonconformant arguments (op1 is %ix%i, op2 is %ix%i)\n', n, m, m2, o);
end
C = [];
if issparse(A) || issparse(B)
C = sparse(o,n);
else
C = zeros(o,n);
end
A = A';
for i=1:n
C(:,i) = outop(bsxfun(inop, A(:,i), B))';
end
C = C';
end
проверено как с разреженными, так и с нормальными матрицами: разрыв производительности намного меньше с разреженными матрицами (3x медленнее), чем с нормальными матрицами (~100x замедлившийся.)
Я думаю, что это медленнее, чем реализации bsxfun, но по крайней мере это не переполнение памяти:
A = randi(10, 1000);
C = genmtimes(A, A');
Если у кого есть лучше предложение, я все еще ищу лучшую альтернативу!