Сводная таблица-как выход в R?
Я пишу отчет, который требует создания ряда сводных таблиц в Excel. Я хотел бы думать, что есть способ сделать это в R, чтобы я мог избежать Excel. Я хотел бы вывести, как скриншот ниже (имена учителей изменены). Насколько я могу судить, я мог бы использовать пакет reshape для вычисления совокупных значений, но мне нужно сделать это несколько раз и каким-то образом получить все данные в правильном порядке. В этот момент я должен просто делать это в Excel. Делает у кого-нибудь есть предложения или рекомендации по пакету? Спасибо!
(редактировать) Данные начинаются со списка учащихся, их учителя, школы и роста. Эти данные затем агрегируются, чтобы получить список учителей со средним ростом класса. Обратите внимание, что учителя группируются по школам. Самая большая проблема, которую я предвижу, делая это с R на данный момент, заключается в том, как вы получаете субтотальные и полные строки (Bsa1 Total, Grand Total и т. д.), поскольку они не являются одним и тем же типом наблюдения как остальные? Вы просто вручную должны рассчитать их и попытаться получить их в правильном порядке, чтобы они появились в нижней части этой группы?
4 ответов
вот образец в битах расчета:
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
require(reshape2)
aggregate(growth ~ school + teacher, data =myDf, FUN=mean)
myDf.melt <- melt(myDf, measured="growth")
dcast(myDf.melt, school + teacher ~ ., fun.aggregate=mean, margins=c("school", "teacher"))
Я не рассматривал форматирование вывода, только расчет. Результирующий фрейм данных должен выглядеть следующим образом:
school teacher NA
1 BSA1 Dick 4.663140
2 BSA1 Harry 4.310802
3 BSA1 Tom 5.505247
4 BSA1 (all) 4.670451
5 BSA2 Dick 6.110988
6 BSA2 Harry 5.007221
7 BSA2 Tom 4.337063
8 BSA2 (all) 5.196018
9 HSA1 Dick 4.508610
10 HSA1 Harry 4.890741
11 HSA1 Tom 4.721124
12 HSA1 (all) 4.717335
13 (all) (all) 4.886576
в этом примере используется пакет reshape2 для обработки промежуточных итогов.
Я думаю, что R-правильный инструмент для работы здесь. Я могу полностью понять, не будучи уверенным, как начать этот анализ. Я пришел в R из Excel несколько лет назад, и сначала это может быть сложно. Позволить мне укажите четыре pro советы, которые помогут вам получить лучшие ответы в Stack Overflow:
1) предоставьте данные, даже если они смоделированы: вы можете увидеть, что я смоделировал некоторые данные в начале моего ответа. Если бы вы предоставили эту симуляцию, это бы а) сэкономило мне время Б) дало вам ответ, который использовал вашу собственную структуру данных, а не тот, который я придумал, и в) другие люди ответили бы. Я часто пропускаю вопросы без данных, потому что я устал гадать о данных, которые им говорят мой ответ отстой, потому что я ошибся.
2) задать один четкий вопрос. "Как я делаю свою работу" - это не единственный четкий вопрос. "Как я могу взять эти данные примера и создать промежуточные итоги в агрегации, как этот пример вывода" - это один конкретный вопрос.
3) постоянно спрашивают! Мы все становимся лучше с практикой. Вы пытаетесь сделать больше в R и меньше в Excel, поэтому вы явно выше среднего интеллекта. Продолжать использовать R и продолжайте задавать вопросы. Со временем все станет проще.
4) Будьте осторожны со своими словами, когда описываете вещи. Вы говорите, что в вашем отредактированном вопросе у вас есть "список" вещей. Список в R-это определенная структура данных. Я подозреваю, что у вас действительно есть фрейм данных и вы используете термин "список" в общем смысле. Это может привести к некоторой путанице. Это также иллюстрирует, почему вы хотите предоставить свои собственные данные.
использование смоделированных данных JD Long и добавление sd и подсчетов:
library(reshape) # not reshape2
cast(myDf.melt, school + teacher ~ ., margins=TRUE , c(mean, sd, length))
school teacher mean sd length
1 BSA1 Dick 4.663140 3.718773 14
2 BSA1 Harry 4.310802 1.430594 9
3 BSA1 Tom 5.505247 4.045846 4
4 BSA1 (all) 4.670451 3.095980 27
5 BSA2 Dick 6.110988 2.304104 15
6 BSA2 Harry 5.007221 2.908146 9
7 BSA2 Tom 4.337063 2.789244 14
8 BSA2 (all) 5.196018 2.682924 38
9 HSA1 Dick 4.508610 2.946961 11
10 HSA1 Harry 4.890741 2.977305 13
11 HSA1 Tom 4.721124 3.193576 11
12 HSA1 (all) 4.717335 2.950959 35
13 (all) (all) 4.886576 2.873637 100
Ниже приведены несколько различных способов создания этого с помощью относительно нового пакета pivottabler.
раскрытие информации: я автор пакета.
дополнительные сведения см. В разделе пакет кран и различные виньетки пакета, доступные на этой странице.
Пример Данных (то же, что и выше)
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
быстрый вывод сводной таблицы на консоль в виде обычного текста
library(pivottabler)
# arguments: qhpvt(dataFrame, rows, columns, calculations, ...)
qpvt(myDf, c("school", "teacher"), NULL,
c("Average Growth"="mean(growth)", "Std Dev"="sd(growth)",
"# of Scholars"="n()"),
formats=list("%.1f", "%.1f", "%.0f"))
извините за автопромоцию, но взгляните на мой пакет expss.
код для генерации вывода ниже:
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
library(expss)
myDf %>%
# 'tab_cells' - variables on which statistics will be calculated
# "|" is needed to suppress 'growth' in row labels
tab_cells("|" = growth) %>%
# 'tab_cols' - variables for columns. Can be ommited
tab_cols(total(label = "")) %>%
# 'tab_rows' - variables for rows.
tab_rows(school %nest% list(teacher, "(All)"), "|" = "(All)") %>%
# 'method = list' is needed for statistics labels in column
tab_stat_fun("Average Growth" = mean,
"Std Dev" = sd,
"# of scholars" = length,
method = list) %>%
# finalize table
tab_pivot()
код выше дает объект, унаследованный от данных.кадр, который может использоваться со стандартными операциями R (подмножество с [ и т. д.). Но есть специальный print метод для этого объекта. Вывод консоли:
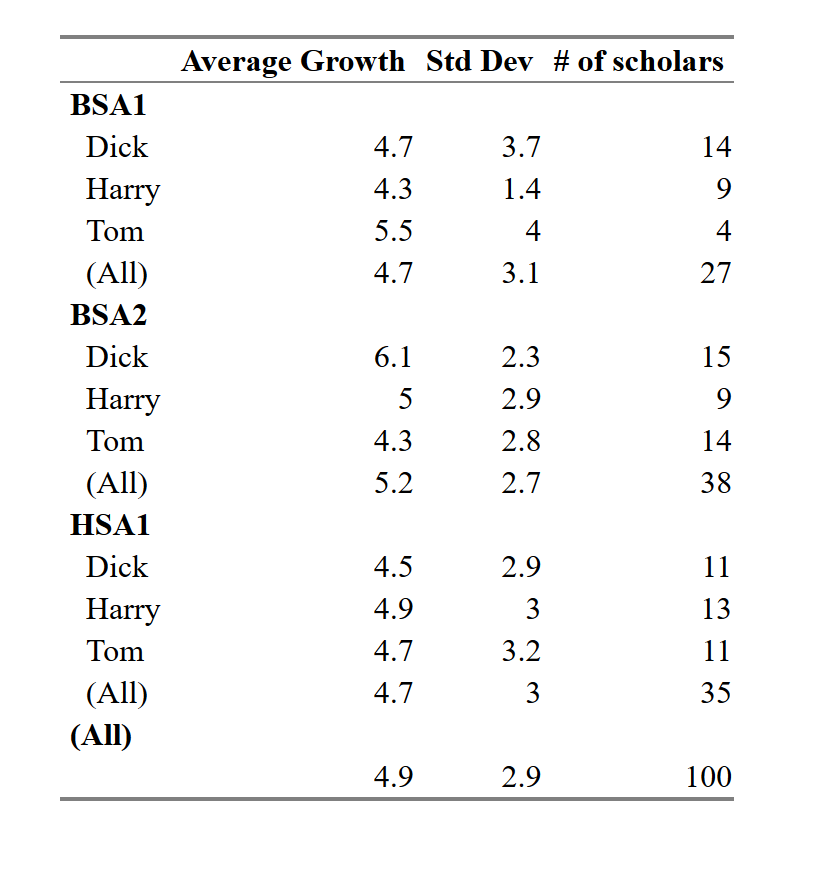
| | | Average Growth | Std Dev | # of scholars |
| ----- | ----- | -------------- | ------- | ------------- |
| BSA1 | Dick | 4.7 | 3.7 | 14 |
| | Harry | 4.3 | 1.4 | 9 |
| | Tom | 5.5 | 4.0 | 4 |
| | (All) | 4.7 | 3.1 | 27 |
| BSA2 | Dick | 6.1 | 2.3 | 15 |
| | Harry | 5.0 | 2.9 | 9 |
| | Tom | 4.3 | 2.8 | 14 |
| | (All) | 5.2 | 2.7 | 38 |
| HSA1 | Dick | 4.5 | 2.9 | 11 |
| | Harry | 4.9 | 3.0 | 13 |
| | Tom | 4.7 | 3.2 | 11 |
| | (All) | 4.7 | 3.0 | 35 |
| (All) | | 4.9 | 2.9 | 100 |
выход через htmlTable в knitr, RStudio viewer или блестящий: